
Designing a Prototype: Postgres Plan Freezing
The story of one extension

This story is about a controversial PostgreSQL feature - query plan freezing extension (see its documentation for details) and the code's techniques underpinning it. The designing process had one specific: I had to invent it from scratch in no more than three months or throw this idea away, and because of that, solutions were raised and implemented on the fly. Time limit caused accidental impromptu findings, which can be helpful in other projects.
Developers are aware of the plan cache module in Postgres. It enables a backend to store the query plan in memory for prepared statements, extended protocol queries, and SPI calls, thereby saving CPU cycles and potentially preventing unexpected misfortunes resulting in suboptimal query plans. But what about sticking the plan for an arbitrary query if someone thinks it may bring a profit? May it be useful and implemented without core changes and a massive decline in performance? Could we make such procedure global, applied to all backends? - it is especially important because prepared statements still limited by only backend where they were created.
Before doing anything, I walked around and found some related projects: pg_shared_plans, pg_plan_guarantee, and pg_plan_advsr. Unfortunately, at this time, they looked like research projects and didn't demonstrate any inspiring ideas on credible matching of cached query plans to incoming queries.
My initial reason to commence this project was far from plan caching: at this time I designed distributed query execution based on FDW machinery and postgres_fdw extension in particular. That project is known now as 'Shardman'. Implementing and benchmarking distributed query execution, I found out that the worst issue, which limits the speed up of queries that have to extract a small number of tuples from large distributed tables (distributed OLTP), is a repeating query planning on each remote server side even when you know that your tables distributed uniformly and the plan may be fully identical on each instance. Working on different solutions, I realised that remote-side queries usually have a much more trivial structure than the origin query and are often similar across various queries (up to different constants). In that case, the most straightforward way was to 'freeze' the plan of the remote-side query and call it again the next time. What can be simpler to implement that by having a plan cache yet in the core?
In general, the idea is relatively trivial: invent a shared library that will employ the planner hook and extension to provide a UI as shown in the picture:
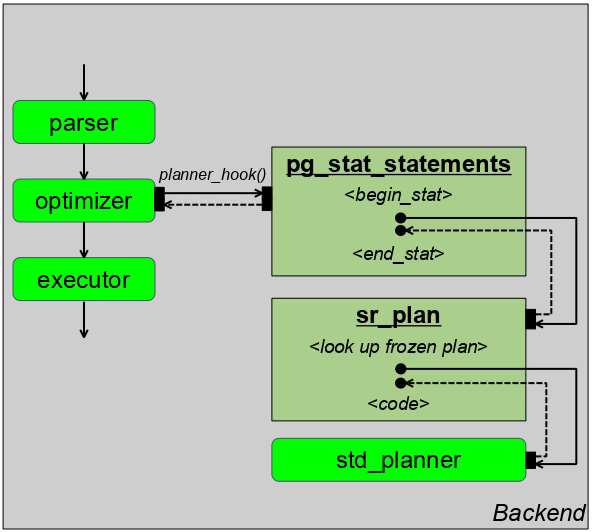
Our extension is labelled as 'sr_plan' on the schema above, abbreviating the phrase 'save/restore plan'. Being the last module in the chain of the planner_hook calls, it can look up the cache of previously stored query plans and, having a positive match, return this plan, avoiding the planning process at all!
So, bravely starting the project, I immediately encountered the first problem: how to match the query to the corresponding plan in the cache? - the SPI, prepared statements, and extended protocol use an internal pointer to the plan or predefined name to identify a plan in the plan cache. That’s not our case: for an arbitrary incoming query, backend has to look at the plan cache and find the query plan that can be correctly used to execute this query. What's more, the initial query string is transformed into an internal representation and passes some stages until the final plan is built. Look at the picture:

Here, you can see that one query can be transformed into multiple parse trees, sometimes having nothing in common with an initial query, through rewriting rules (which can be altered before the next time the query comes). In its turn, each parse tree can be implemented by multiple query plans…. Remember that indexes used in the plan are not mentioned in the query or corresponding parse tree.
Rewriting rules, table names, sets of columns and indexes - all that stuff can also be altered. Moreover, I predict the user will complain if changing just one backspace in the query ends up causing a loss of matching with the frozen plan. It's quite an erratic technique, isn't it? Summarising issues mentioned above, we can't just remember query string and corresponding plan to prove that this plan may be used for execution of this query.
After spending a couple of days, I realised that the only proof that the specific cached plan may rightly execute the query is the equality of parse trees plus some checking of indexes mentioned in the plan. Match parse trees? Easy! Just use the in-core routine equal() - that's enough!
Altering database objects is not an issue in this scheme. The plan cache's invalidation machinery guarantees that if some object mentioned in the plan is altered, all plans mentioning it will be marked as 'invalid'.
Matching parse trees instead of query text has one more positive outcome: internal representation is stable to many changes in query text, like backspaces or upper/lower case letters. But as usual, it has some negatives: comparing trees is not so cheap. Imagine you have frozen 100 query plans in the cache. How much overhead do you get by comparing each incoming query around 100 times? And what if this query even out of the frozen set?
Fortunately, since Postgres 13, this question has had a quick and terse answer: queryId. This is an in-core feature to generate hash value for each query tree. This hash is based on most of the query elements, such as tables, expressions and constants. Look at this picture:
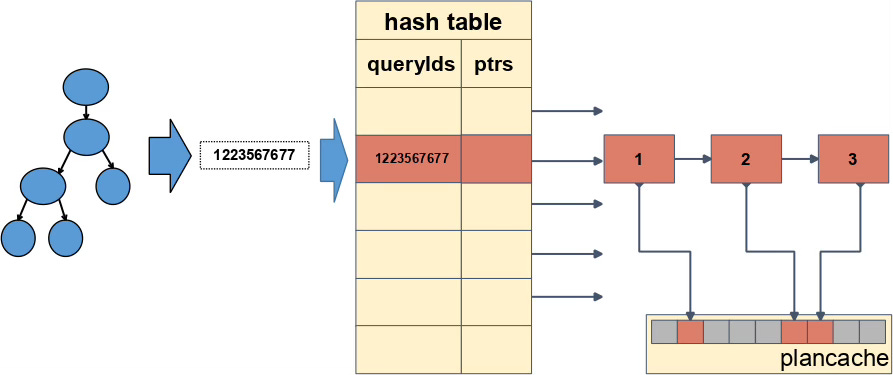
Having queryId, we can invent a hash table with queryId as a key. Entry of this hash table contains a pointer to the head of a list of frozen plans with the same queryId. Instead of passing through all 100 frozen plans, we only need to match a small fraction. Quick experiments have shown that with queryId generated by the standard JumbleQuery technique, we almost always have only one plan in the class with the same queryId.
Hmm, you might dubiously say: what about parameterised queries? If we want to use a frozen plan for arbitrary incoming queries, we have to store a parameterised, aka 'generic', plan and employ it to execute incoming queries with constants instead of parameters. How queryId could help us in this case?
This question didn't have an easy answer. Having experience with the autoprepare feature, I remember how many hurdles a developer must overturn if all the constants in the plan are replaced with parameters before freezing. What is less obvious is that one parameterised plan may be effective for one set of constants and totally worst for another.
So, we have to know which position in an expression to treat as a parameter. The solution I invented here was trivial: give a choice to the user (with hidden hope to invent an analysing procedure in the future to find correlations in parameters and plans have built) and divide the freezing procedure into two stages: registration and sticking into the plan cache.
Registration tells our extension that the query with a specific queryId is under control, and each plan generated for this query must be nailed down in the backend's plan cache, rewriting the plan built during the previous execution. In our UI, it looks like a query:
SELECT sr_register_query(query_string [, parameter_type, ...]);
For example:
SELECT sr_register_query('SELECT count(*) FROM a WHERE x = $1');Using '$N' in the query, you point out parameterised parts of the incoming query. Parameter type allows to force the type of each parameter. Registration stores the query text, query tree, and set of parameters (with their positions in the tree) inside the extension memory context.
Registration impacts only the backend where it was registered. Afterwards, you can play locally with any GUCs, hints, or anything else to achieve the desired query plan without fear of influencing the instance's performance. After that, by executing the following query:
SELECT sr_plan_freeze();you can stick the plan in the local backend and it will be lazily pass to the plan caches of other backends registered in the same database. Spreading across the instance's backends is relatively trivial - just employ DSM hash tables and a flag to signal backends to check the consistency of their caches with the shared storage. Serialisation/deserialisation routines can transform to the string a query tree as well as the query plan. But how do we implement parameterisation?
Easy to say, but hard to solve. At first, I changed the queryId generation algorithm to ease the accuracy of the hash generation by excluding the fact that the tree node is a parameter and considering only its data type and position in the query tree. Of course, it means a core patch, but it is only a couple of code lines. As a result, parameterised query and query with constants in the place of parameters has the same queryId and since then we can find frozen plan in the cache.
The second problem is much more severe. Playing with queries after registration, the user will use queries with specific constant values instead of parameters. After matching queryId we must prove identity of parse trees by calling the equal() routine. But it can't match the incoming constant and registered parameterised query trees without invasive changes to the core logic. Having only a month to the deadline, I discovered an essential design trick: before the query tree comparison procedure, just replace Const nodes with corresponding Param nodes in positions of the query tree defined by the user manually on registration. To make the text a bit more easy to understand, let me illustrate this technique with the following trivial picture:
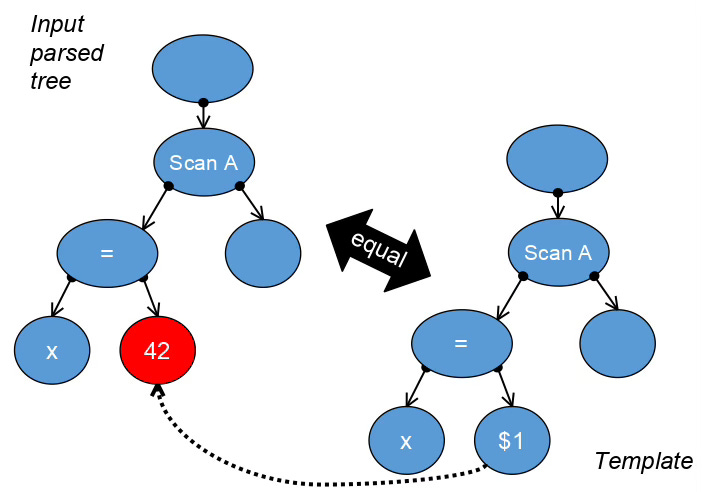
As you can see, we introduced the abstraction named the 'template query tree' that may be even more extensively used in the future to match queries where the difference is only in database object aliases.
This technique definitely adds some overhead and complexity to the code, but remember, we are oriented on sophisticated queries where the optimiser fails to make an appropriate plan. By profiting from reduced disk fetches because of a good plan, we can allow backend to spend more CPU cycles. Moreover, value of the overhead mostly depends on the queryId technique: how good it is in separating queries into classes.
The third question of this technique was even more challenging to answer: having incoming constants and a parameterised plan to execute the query, how do we pass these constants to the executor? PostgreSQL architecture doesn't allow it to be done because specific parameter values are managed at higher levels of execution machinery. Having spent most of the remaining time, I invented one trick: insert at the top of the frozen plan a CustomScan node, which does nothing except alter the set of parameter values in the execution state structure at the beginning of execution. With this approach, EXPLAIN of a frozen query looks like below:
EXPLAIN SELECT count(*) FROM a WHERE x = 1::bigint;
Custom Scan (SRScan)
Plan is: tracked
Query ID: -5166001356546372387
Parameters: $1 = 1
-> Aggregate
-> Seq Scan on a
Filter: (x = $1)As you can see, having such a node has earned us one positive outcome: this node informs the user about the state of the query plan. It can also potentially gather additional statistics and use them later to make decisions about unfreezing.
Afterwards, I passed PostgreSQL with this extension through a series of benchmarks. The most difficult was, of course, pgbench: it contains too trivial queries executing in too small periods of time that our overheads, even the queryId calculation, should be highlighted here. After manually freezing all its queries, I found out that pgbench results improved by around 15%- 25% on average. Amazing!
One more simple trick for storing frozen plans on disk in a specific file of the data catalogue to survive crushes and reboots — and the prototype is ready for demonstration. But I forgot about real-life cases: DDL, upgrades, and migrations. If an object mentioned in the plan is altered (for example, add a column to the table), Postgres marks the plan as 'invalid'. But it is impractical for us: we should unfreeze the query only if proved that the plan is totally incorrect in the context of this query and database. To be practical, our extension should survive such disasters.
In just a few days, I could invent only an obvious solution called the 'validation procedure'.
Through the validation procedure, the extension checks that the plan can still be applied to a specific query. How it works? - relatively trivial: just open a subtransaction (to survive errors) and pass the query text parsing procedure - It is precisely the reason why we store registered query text. If the query tree is the same as the stored one, it is a good sign that the objects mentioned in the query still exist. So, we need only to check the consistency of indexes mentioned in the query plan. That's enough to mark the query plan as frozen and valid.
The validation procedure allows for the survival of transaction isolation levels: some backends can already see the schema changes and 'unfreeze' query, while others may reuse the frozen plan for the same query. Moreover, a previously invalid plan can be validated on ROLLBACK, and the query can be returned to a frozen state.
What is more interesting is that we can try to pass the frozen query plan to other instances using the validation procedure. The technique looks similar to the above: on a new instance, open a subtransaction, deserialise the query tree and plan, execute the parsing procedure for the query text, recalculate queryId (OIDs of objects may be different), and compare the deserialised query tree with the parsed one. If they are identical, check the indexes and probe query execution to ensure nothing special was broken. Remember, here we should have one more additional structure: 'oid → object name' translation table to identify oids for the database objects in the case of dump/restored or logically replicated database.
Of course, in the case of an upgrade, this technique is vulnerable: we can get a SEGFAULT during deserialisation because of the difference in ABI. What's worse, the plan may be deserialised correctly, but the execution state could contain some specific data or logic that could be altered in the next Postgres version and incompatible with the plan. So, this technique looks applicable mostly for migrations between the same versions of the binaries rather than for upgrades.
Do we have any options to survive an upgrade? Yes - thanks to Michael Paquer and the developer's team in NTT for inventing the pg_hint_plan extension. Before the upgrade, we can store each query text with a set of hints, dropping away the parse tree and the plan. After the upgrade, we should pass parsing and optimisation procedures for each query with the hope that hints will direct the optimiser to build the plan we want to obtain.
That's all I wanted to tell you about this case. Be brave, think openly, and you could invent new directions for DBMS development! As usual, you can play with the extension using the binary version for Postgres 15.
In the end, I urge you to reflect on this post and discuss in comments how interesting the idea of plan freezing is. What is the perspective scope for this feature? What do you think about plan validation?
THE END.
July 28, 2024. Thailand, South Pattaya.