
Does Postgres need an extension of the ANALYZE command?
One more idea on the Postgres extension

In this post, I would like to discuss the stability of standard Postgres statistics (distinct, MCV, and histogram over a table column) and introduce an idea for one more extension - an alternative to the ANALYZE command.
My interest in this topic began while wrapping up my previous article when I noticed something unusual: the results of executing the same Join Order Benchmark (JOB) query across a series of consecutive runs could differ by several times and even orders of magnitude - both in the value of the execution-time and in pages-read.
This was puzzling, as all variables remained constant - the test script, laptop, settings, and even the weather outside were the same. This prompted me to investigate the cause of these discrepancies… .
In my primary activity, which is highly connected to query plan optimisation, I frequently employ JOB to assess the impact of my features on the planner. At a minimum, this practice enables me to identify shortcomings and ensure that there hasn't been any degradation in the quality of the query plans produced by the optimiser. Therefore, benchmark stability is crucial, making the time spent analysing the issue worthwhile. After briefly examining the benchmark methodology, I identified the source of the instability: the ANALYZE command.
In PostgreSQL, statistics are computed using basic techniques like Random Sampling with Reservoir, calculating the number of distinct values (ndistinct), and employing HyperLogLog for streaming statistics - for instance, to compute distinct values in batches during aggregation or to decide whether to use abbreviated keys for optimisation. Given that the nature of statistics calculation is stochastic, fluctuations are expected. However, the test instability raises the following questions: How significant are these variations? How can they be minimised? And what impact do they have on query plans? Most importantly, how can we accurately compare benchmark results when such substantial deviations are present, even in the baseline case?
Is it possible to achieve query plan stability?
Well, I've thought: the tables are massive, and there are a lot of rows inside - let's just increase the value of the default_statistics_target parameter, and that will solve the problem, right? I was gradually increasing the sample size for statistics from 100 to 10000, re-running all benchmark queries and recording how the pages-read criterion behaves:



Even with the highest level of statistical detalisation, query plans still change after re-executing the ANALYZE command. While increasing the sample size from 100 to 10,000 may improve something, this does not fundamentally alter the situation. Such significant instabilities call into question the possibility of independently reproducing benchmarks and conducting comparative results analyses without examining the query plans.
Now, let's dig deeper: what generally fluctuates? Using a simple script, I conducted an experiment to collect scalar statistics (stanullfrac, stawidth, stadistinct) by rebuilding the statistics ten times. The script for this operation might look like this:
CREATE TABLE test_res(expnum integer, oid Oid, relname name,
attname name, stadistinct real,
stanullfrac real, stawidth integer);
DO $$
DECLARE
i integer;
BEGIN
TRUNCATE test_res;
FOR i IN 0..9 LOOP
INSERT INTO test_res (expnum,oid,relname,attname,stadistinct,stanullfrac,stawidth)
SELECT i, c.oid, c.relname, a.attname, s.stadistinct, s.stanullfrac, s.stawidth
FROM pg_statistic s, pg_class c, pg_attribute a
WHERE c.oid >= 16385 AND c.oid = a.attrelid AND
s.starelid = c.oid AND a.attnum = s.staattnum;
ANALYZE;
END LOOP;
END; $$Afterwards, I analysed the results with a query like the following:
WITH changed AS (
SELECT
relname,attname,
(abs(max - min) / avg * 100)::integer AS res, avg
FROM (
SELECT relname,attname,
max(stadistinct) AS max, avg(stadistinct) AS min,
avg(stadistinct) AS avg
FROM test_res
WHERE relname <> 'test_res'
GROUP BY relname,attname
)
WHERE max - min > 0 AND abs(max - min) / avg > 0.01
) SELECT relname,attname, res AS "stadistinct dispersion", avg::integer
FROM changed t
ORDER BY relname,attname;Something more mathematically correct could be used here, but for our purposes, such a simple criterion is enough to see the instability of statistics. Using the above scripts, let's see how ndistinct fluctuates for 100, 1000 and 10000 elements of the statistical sample:
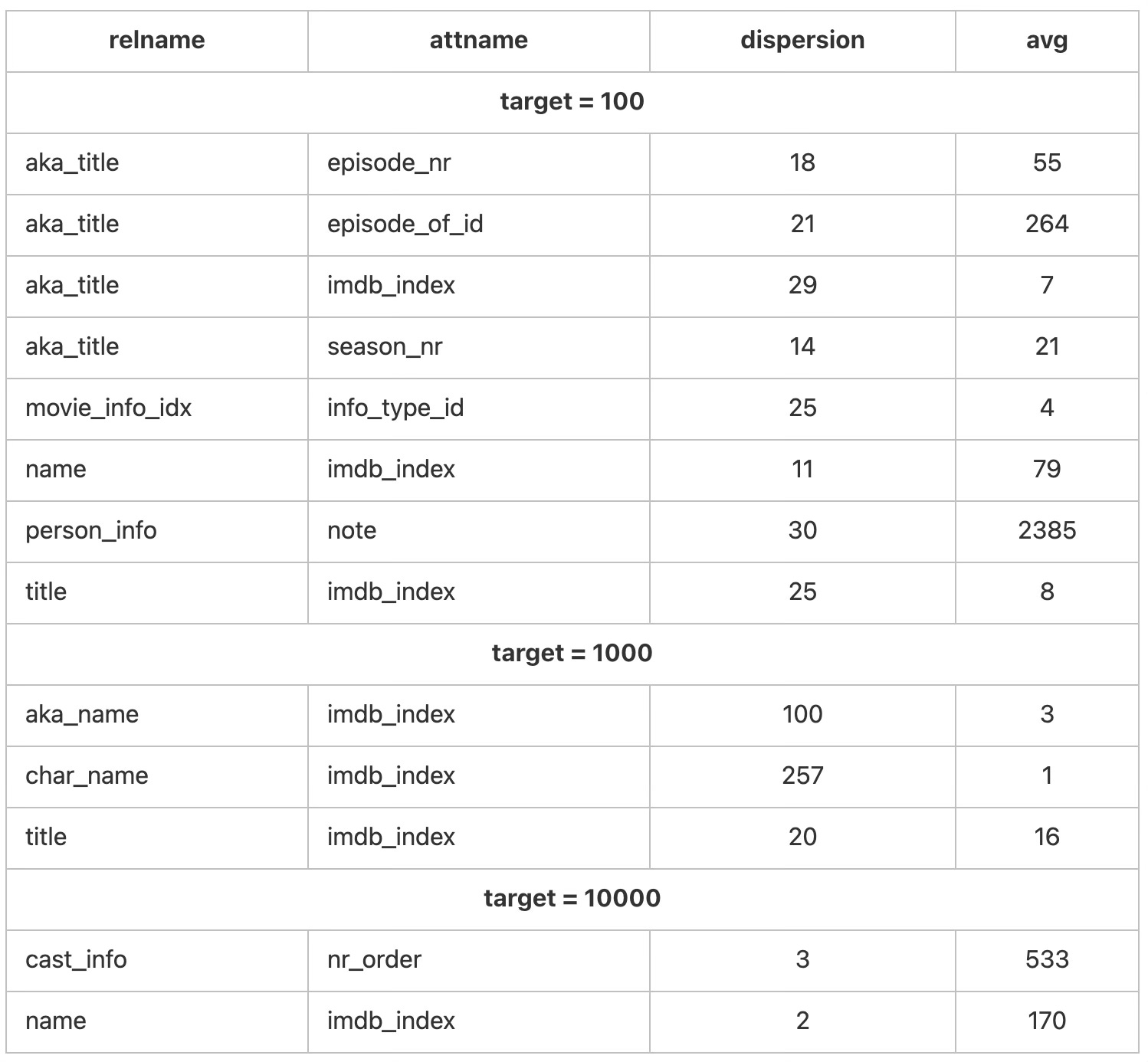
Stochastic, right? There's a lot of strange stuff here, but we won't dig too deep, attributing it to the fact that determining the ndistinct value from a small sample does not converge uniformly to the actual value. Yes, the fluctuations subside with the sample size, but 10,000 is already the limit, and the table sizes in this benchmark are not that big - in real life, statistics can remain unstable on much larger tables.
Another observation from the results of this experiment is that statistics on fields with a large number of duplicates suffer the most. In practice, this means that grouping or joining on some harmless "Status" field can cause immense estimation errors inside the optimiser, even if the expression on this field is only part of a long list of expressions in the query.
What exactly is the origin of instability?
However, what exactly causes the query plans to fluctuate in this benchmark? To do this, we need to look at the query plans. One query consistently changes its plan from iteration to iteration - 30c.sql, which makes it convenient to analyse. Comparing the query plans, we can see that HashJoin and the parameterised NestLoop compete with very close estimates (see here and here). Using the "close look" method, I found that the discrepancies in the estimates begin already at the SeqScan stage and then diverge throughout the entire plan:
-> Parallel Seq Scan on public.cast_info
(cost=0.00..498779.41 rows=518229 width=42)
Output: id, person_id, movie_id, person_role_id,
note, nr_order, role_id
Filter: (cast_info.note = ANY ('{(writer),
"(head writer)","(written by)",(story),"(story editor)"}'))
-> Parallel Seq Scan on public.cast_info
(cost=0.00..498779.41 rows=520388 width=42)
Output: id, person_id, movie_id, person_role_id,
note, nr_order, role_id
Filter: (ci.note = ANY ('{(writer),
"(head writer)","(written by)",(story),"(story editor)"}'))There is a slight difference in the estimation of the number of rows selected from the table. Let's dig deeper and see why.
It is not easy to compare histograms or MCV, so let's just study our specific query or, more precisely, the problematic scan operator. The estimation of x = ANY (...) occurs by estimating each individual expression x = Ni and then adding up the probabilities. In our case, all five Ni constants are included in the MCV statistics - which means that even the ndistinct value will not be used by Postgres. Thus, the estimation should be as accurate and stable as possible. However, if you dig into the numbers, you can see that after the ANALYZE, the frequency of each of the sample elements changes. For example, for default_statistics_target=10000:
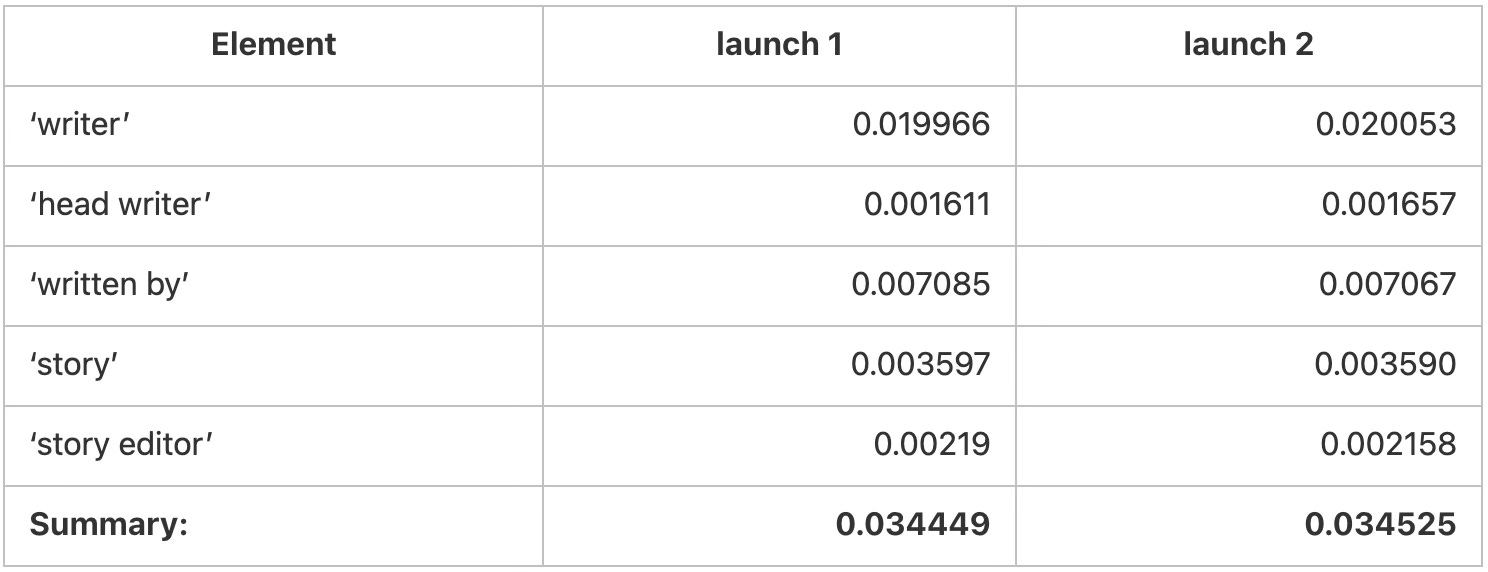
The final estimation changes by about 1%, which is not too much in principle. However, who knows - maybe we didn't hit a horrid probability? In addition, the error accumulates when planning the higher-level operators of the query tree, ultimately changing the plan of this query.
In general, this corresponds to the theory that calculating the number of distinct in a set of values with reasonable accuracy can only be obtained by analysing almost all the table rows. Moreover, the issue with statistics has already been reported to the community [here and here, for example] and an attempt to solve the problem was conducted. However, in any case, this comes up against an expensiveness of the volume of the statistical sample and is not universally applicable - and therefore not applicable in the PostgreSQL core.
However, for analytical tasks, where the size and denormalisation of the scheme impose increased requirements on the quality of statistics, one computationally expensive pass through the table's rows may make sense. In addition, the data is loaded rarely in large batches, and statistical collection is not required often. So maybe we just probe the approach involving the extension mechanism?
An extension for standard statistics
How to design it? Let's recall the article by DeWitt1998 - the author suggested computing statistics attaching to sequential table scans. Postgres has a CustomScan node mechanism that can be inserted into any part of the query plan and implemented with an arbitrary complexity of the operation. Therefore, such an idea is easy to implement. Also, no one prevents you from adding a new function to the UI using an extension that will go through the entire table and calculate at least ndistinct and MCV with maximum accuracy.
Having standard "lightweight" statistics on the number of ndistinct, you can assess how expensive and feasible it will be in terms of computing resources before deciding to launch such an analysis procedure.
Feeding such refined statistics to the optimiser can be implemented employing two hooks: get_relation_stats_hook and get_index_stats_hook. They allow to replace the standard statistics obtained from pg_statistic with an alternative, as long as it corresponds to the internal Postgres tuple format. The second hook is exciting because it can be used to implement not complete statistics but predicate statistics - that is, statistics based on data selected from a table with a particular filter - an analogue of SQL Server's CREATE STATISTICS ... WHERE ... .
How to store statistics? For the optimiser to be able to use them correctly, it is evident that their storage format must correspond to the format of storing standard statistics. Nothing is complicated about this since the extension can create its tables - so why not just create table pg_statistic_extra?
Additional bonuses from creating such an extension may emerge entirely unexpectedly. For example, while writing this post, I realised that it could help solve the dilemma of statistics on a partitioned table: no one likes to spend resources on it since it duplicates the work of calculating statistics for each individual partition. At the same time, it does not change much over time: there are many partitions, and if the data is well spread out, then the statistics for all data change insignificantly (except, perhaps, for the partition key). In addition, the table can be huge, and things like ndistinct in standard statistics can be far from reality. With the help of the extension, you can implement the creation of detailed statistics by event: attach/detach partition, at the time of massive updates, etc., which can allow you to launch a computationally expensive operation more consciously. Also, knowing that the table changes rarely, it will be possible to radically simplify the statistics calculation by using indexes or implementing other sampling algorithms (for example, this one)...
That's actually the whole roadmap. All that's left is to find a passionate student, and you can apply with a project to GSoC ;). What do you think about such an extension? Write in the comments.
THE END.
February 2, 2025, South Pattaya, Thailand.
Thanks, very nice article!
There may be an error in your query :
"avg(stadistinct) AS min" instead of "min(stadistinct) AS min"