
Investigating Memoize's Boundaries
Compare Postgres & SQL Server query plans

During the New Year holiday week, I want to glance at one of Postgres' most robust features: the internal caching technique for query trees, also known as memoisation.
Introduced with commit 9eacee2 in 2021, the Memoize node fills the performance gap between HashJoin and parameterised NestLoop: having a couple of big tables, we sometimes need to join only minor row subsets from these tables. In that case, the parameterised NestLoop algorithm does the job much faster than HashJoin. However, the outer size is critical for performance and may cause NestLoop to be rejected just because of massive repetitive scans of inner input.
When predicting multiple duplicates in the outer column that participate as a parameter in the inner side of a join, the optimiser can insert a Memoize node. This node caches the results of the inner query subtree scan for each parameter value and reuses these results if the known value from the outer side reappears later.
This feature is highly beneficial. However, user migration reports indicate that there are still some cases in PostgreSQL where this feature does not apply, leading to significant drops in query execution time. In this post, I will compare the caching methods for intermediate results in PostgreSQL and SQL Server.
Memoisation for SEMI/ANTI JOIN
Let me introduce a couple of tables:
DROP TABLE IF EXISTS t1,t2;
CREATE TABLE t1 (x integer);
INSERT INTO t1 (x)
SELECT value % 10 FROM generate_series(1,1000) AS value;
CREATE TABLE t2 (x integer, y integer);
INSERT INTO t2 (x,y)
SELECT value, value%100 FROM generate_series(1,100000) AS value;
CREATE INDEX t2_idx ON t2(x,y);
VACUUM ANALYZE t1,t2;In Postgres, a simple join of these tables prefers parameterised NestLoop with memoisation:
EXPLAIN (COSTS OFF)
SELECT t1.* FROM t1 JOIN t2 ON (t1.x = t2.x);
/*
Nested Loop
-> Seq Scan on t1
-> Memoize
Cache Key: t1.x
Cache Mode: logical
-> Index Scan using t2_idx on t2
Index Cond: (x = t1.x)
*/The smaller table t1 contains many duplicates in the column used for the JOIN, while the bigger one t2 contains almost unique values. It also has an index to extract necessary tuples effectively.
Ok, it works for trivial joins. What about more complex forms, like SEMI JOIN? Look at the query:
EXPLAIN (COSTS OFF)
SELECT * FROM t1 WHERE x IN (SELECT y FROM t2 WHERE t1.x = t2.x);
/*
Nested Loop Semi Join
-> Seq Scan on t1
-> Index Only Scan using t2_idx on t2
Index Cond: ((x = t1.x) AND (y = t1.x))
Filter: (x = y)
*/Postgres can pull-up the subquery and transform it into a join. But it doesn't add a Memoize node in that case. To compare, execute this query in SQL Server (Use the OPTION (LOOP JOIN) hint to prevent hash join):
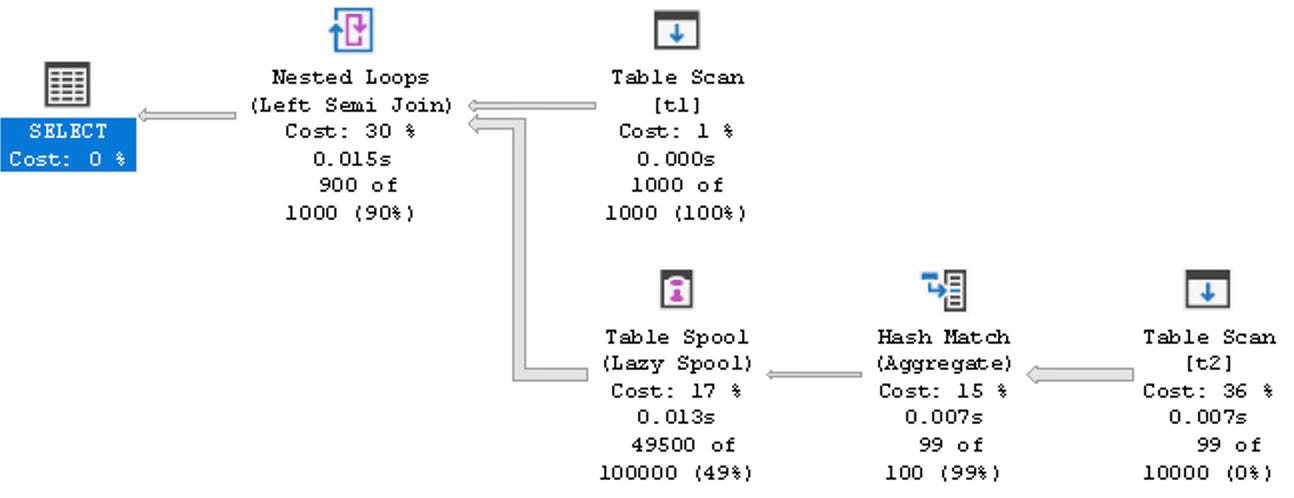
SQL Server performs a similar optimisation and utilises a Spool node in the inner subtree of a join. This approach allows the results of scans on the inner side of the join to be cached. Interestingly, it doesn't have to cache individual tuples; it only needs to keep track of the existence of the NULL/NOT NULL result.
So, why hasn’t Postgres implemented Memoize for JOIN_SEMI? If you examine the code, you will find that this limit was introduced in an initial commit by David Rowley.
if (!extra->inner_unique && (jointype == JOIN_SEMI ||
jointype == JOIN_ANTI))
return NULL;In the case of a semi-join, the executor only requires the first tuple from the inner subtree to make its decision. This means that the Memoize cache will contain incomplete results, which is (I suppose) a source of concern for developers. However, the MemoizePath struct already has built-in mechanisms for situations where the inner subtree provably produces a single tuple for each scan.
It appears that much of the groundwork is already in place to implement caching for semi-joins. We need to make minor adjustments to the get_memoize_path function, revise the cost model in the cost_memoize_rescan routine, and inform users about the memoisation mode by adding relevant details to the EXPLAIN output. The code that enables memoisation for semi-joins is relatively concise and can be found in the branch of my GitHub project. With this patch applied, you can see something like this:
EXPLAIN (COSTS OFF)
SELECT x FROM t1 WHERE EXISTS (SELECT x FROM t2 WHERE t2.x=t1.x);
/*
Nested Loop Semi Join
-> Seq Scan on t1
-> Memoize
Cache Key: t1.x
Cache Mode: logical
Store Mode: singlerow
-> Index Only Scan using t2_idx on t2
Index Cond: (x = t1.x)
*/The EXPLAIN parameter 'Store Mode' appears only when the Memoize node works in the 'incomplete' mode. The same way it works for ANTI JOIN cases:
EXPLAIN (COSTS OFF)
SELECT x FROM t1 WHERE NOT EXISTS (SELECT x FROM t2 WHERE t2.x=t1.x);
/*
Nested Loop Anti Join
-> Seq Scan on t1
-> Memoize
Cache Key: t1.x
Cache Mode: logical
Store Mode: singlerow
-> Index Only Scan using t2_idx on t2
Index Cond: (x = t1.x)
*/In real-life scenarios, I frequently see on the inner side of SEMI and ANTI joins not trivial table scans but huge subtrees containing join trees, aggregates and sortings. For such queries, avoiding unnecessary rescan calls is crucial. Even more importantly, knowledge of the only single tuple needed from such a subquery may cause the choice of a more optimal fractional path.
Memoise arbitrary query subtree
Here, I want to discover if the optimiser can use Memoize to cache the result of a bushy query tree. Look at the example:
DROP TABLE IF EXISTS t1,t2,t3;
CREATE TABLE t1 (x numeric PRIMARY KEY, payload text);
CREATE TABLE t2 (x numeric, y numeric);
CREATE TABLE t3 (x numeric, payload text);
INSERT INTO t1 (x, payload)
(SELECT value, 'long line of text'
FROM generate_series(1,100000) AS value);
INSERT INTO t2 (x,y)
(SELECT value % 1000, value % 1000
FROM generate_series(1,100000) AS value);
INSERT INTO t3 (x, payload)
(SELECT (value%10), 'long line of text'
FROM generate_series(1,100000) AS value);
CREATE INDEX t2_idx_x ON t2 (x);
CREATE INDEX t2_idx_y ON t2 (y);
VACUUM ANALYZE t1,t2,t3;
-- Disable any extra optimisations:
SET enable_hashjoin = f;
SET enable_mergejoin = f;
SET enable_material = f;Now, let's discover the query:
EXPLAIN (COSTS OFF)
SELECT * FROM t3 WHERE x IN (
SELECT y FROM t2 WHERE x IN (
SELECT x FROM t1)
);There are three joining tables. In the absence of a hash join, it would be better to use a parameterised scan. Lots of duplicated values inside Table t3 should trigger the use of the memoisation technique:
Nested Loop Semi Join
-> Seq Scan on t3
-> Nested Loop
-> Index Scan using t2_idx_y on t2
Index Cond: (y = t3.x)
-> Index Only Scan using t1_pkey on t1
Index Cond: (x = t2.x)As you can see in the EXPLAIN above, Postgres can’t insert a Memoize node at the top of NestLoop JOIN. As far as I remember, it has not yet been implemented because it is hard to discover the query subtree and find all the lateral references and parameters that are mandatory for the memoisation technique. At the same time, SQL Server is capable of doing it:
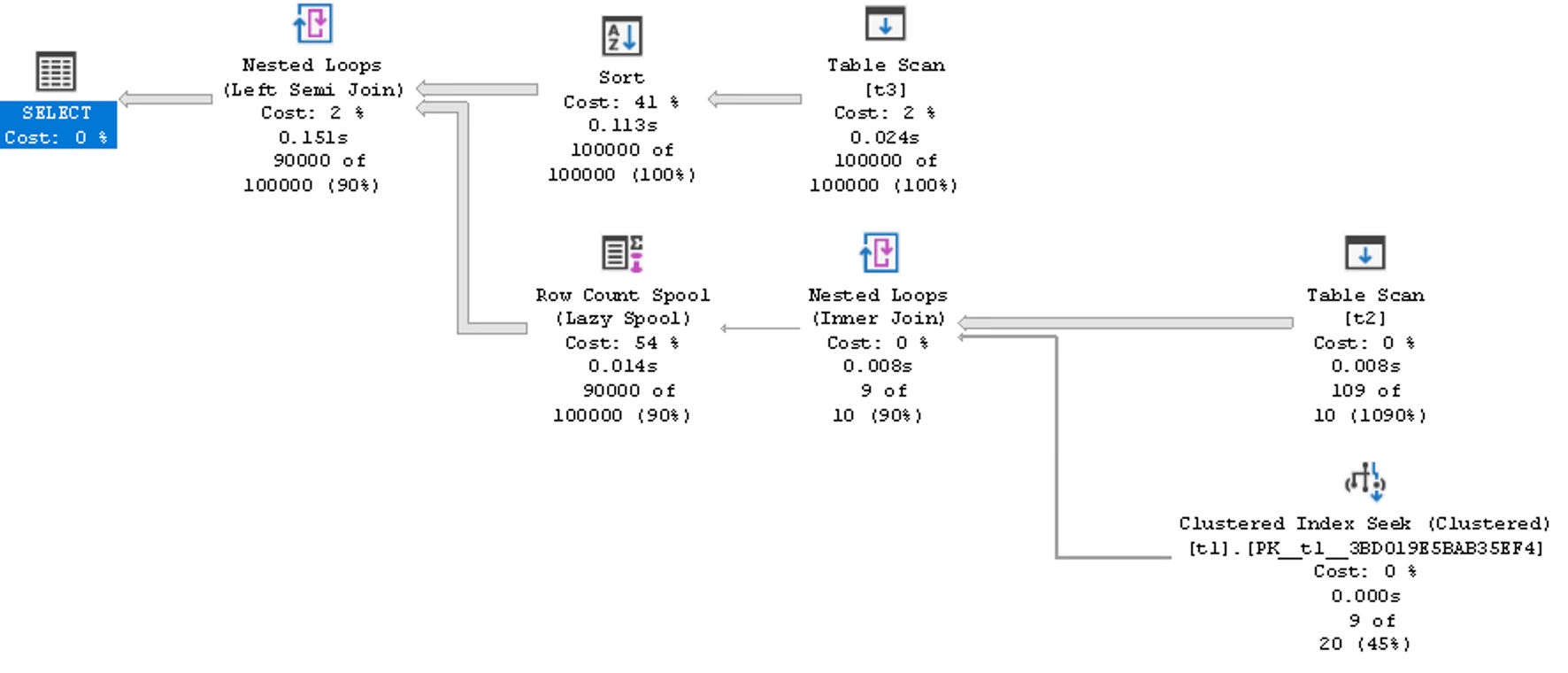
A closer examination of this example revealed an interesting aspect. Although Postgres doesn't have the opportunity to insert Memoize over the join, it might still insert Memoize over trivial scans of tables t1 or t2, thereby avoiding repeated scans. However, it didn't do this because it predicted only one rescan operation when planning the JOIN(t1,t2). In this case, using memoisation seems unnecessary.
One million rescan cycles occur due to the upper-level join, JOIN(t3, JOIN(t1,t2)), but the bottom-up optimiser lacks the insight to identify this valuable data at the level of JOIN(t1,t2). You can observe this behaviour in our test example by populating t3.x with unique data. Interestingly, SQL Server also uses a bottom-up planning strategy and fails to recognise this situation to insert an appropriate Spool node.
Postgres planning extensibility allows passing through the query plan and doing additional work. Should we consider adding a top-down planning cycle after constructing the query plan?
Beyond the NestLoop memoisation
In previous sections, we discussed how memoisation could be enhanced by extending it to other join types and applying it to arbitrary query subtrees. But can we go further? Let me dream for a little bit...
Memoisation is a technique used for caching parameters along with their corresponding results. In many real-world scenarios, I often encounter complex situations where a heavy subplan is evaluated within an expression or a CASE statement for every incoming tuple due to references to upper-query objects.
What if the optimiser could insert a Memoize node at the top of the subplan whenever an external value parameterises it? To illustrate this idea, let me provide an example:
-- Case 1:
EXPLAIN (COSTS OFF)
SELECT oid,relname FROM pg_class c1
WHERE oid =
CASE WHEN (c1.oid)::integer%2=0
THEN (SELECT oid FROM pg_class c2 WHERE c2.relname = c1.relname)
ELSE
(SELECT oid FROM pg_class c3 WHERE c3.relname = c1.relname)
END;
-- Case 2:
EXPLAIN (VERBOSE, COSTS OFF)
SELECT
CASE WHEN (c1.oid)::integer%2=0
THEN (SELECT oid || ' - TRUE' FROM pg_class c2 WHERE c2.relname = c1.relname)
ELSE
(SELECT oid || ' - FALSE' FROM pg_class c3 WHERE c3.relname = c1.relname)
END
FROM pg_class c1;
-- Case 3:
EXPLAIN (COSTS OFF)
SELECT oid FROM pg_class c1
WHERE EXISTS (
SELECT true FROM pg_class c2 WHERE c1.relname=c2.relname OFFSET 0);We can't flatten subplan nodes in these examples and must evaluate them repeatedly. In my mind, the optimiser should have a chance to build a plan that looks like the below:
SubPlan 1
Memoize
Cache Key: ((c1.oid)::integer % 2)
Cache Mode: logical
-> Index Scan using pg_class_relname_nsp_index on pg_class c2
Index Cond: (relname = c1.relname)In this case, the Memoize node will re-evaluate the underlying subplan only when a new combination of parameters is provided from the upper query. While we cannot address all the issues that arise with the subplan bubbling up in an expression, we can help mitigate performance cliffs caused by such constructs.
Do you think it makes sense?
THE END.
January 2, 2025, Pattaya, Thailand.