
MSSQL query plan optimisation advantages
Notes on the cases when MSSQL outperform PostgreSQL: parallelism and selectivity estimation of join clauses

For years, we discovered the Oracle DBMS to make PostgreSQL more delicious for users who want an alternative. Many of their exciting technologies have been adopted: remember the SQL profile or SQL plan baseline features implemented in PostgreSQL in the form of AQO and sr_plan extensions correspondingly. In some aspects, like automatic reoptimisation, PostgreSQL has solutions outperforming Oracle analogues in some aspects.
While Oracle has undoubtedly introduced many impressive solutions, the transition from Oracle to PostgreSQL has been remarkably smooth. We've seen a significant reduction in migration challenges, with most migrations proceeding without a hitch. We've even developed the extension of client session variables to facilitate migration. Admittedly, many of these solutions are under enterprise license. However, in the PostgreSQL world, it's not uncommon for popular codes to find their way into the core, isn’t it?
However, the landscape changes when it comes to MSSQL to PostgreSQL migrations. We've encountered some challenges, with clients reporting significant query slowdowns during migration benchmarks. These problematic queries are diverse, and the environment and database sizes vary from gigabytes to terabytes. In some instances, queries have become so unoptimised that even after two weeks of execution, they remain unfinished, a stark contrast to the 20 ms execution time in MSSQL. This is not a mere stumbling block but a testament to the technological superiority we're dealing with, prompting me to analyse these cases.
The problem
The first case I want to show looks relatively trivial. Let’s see the schematic:
HashAggregate (width=1002) (actual time=4000s rows=2.1E3)
Group Key: t1.x1, t1.x2, t1.x3, t1.x4
-> Nested Loop (width=662) (actual time=500s rows=1.5E9)
-> Seq Scan on t1 (actual time=0.3s rows=2.4E5)
-> Index Scan using t2_idx on t2 (actual time=0.3E-4 rows=11)
Index Cond: t2.x1 = t1.x1 AND t2.x2 = t1.x2
Filter: t2.x3 = t1.x3 AND t2.x4 = t1.x4
Rows Removed by Filter: 0Here, t1 and t2 - are two temporary tables containing around 2E5 tuples each.
Here, we have one JOIN over two not-so-huge tables and aggregation at the top. This join generates a massive number of tuples - more than one billion, and because of that, it works for around nine minutes. But what’s really interesting here is trivial hashed GROUP-BY, which consumes about one hour! Keeping in mind how trivial this operation usually is, it looks weird. That is the main reason for scrutinising that case; MSSQL executes this query in only 300s.
Analysis
Something must be a reason, right? So, look into the MSSQL Plan schematic:
HashAggregate (parallel 8 streams)
Hash Join
Index Scan t1
Index Scan t2Comparing MSSQL and PostgreSQL Plans, we see some differences. At first, HashJoin seems to be the better option. But, the replacement of NestLoop with HashJoin gives us only a tiny speedup (300s instead of 500s) and doesn’t influence the total execution time much. The second difference - is parallel execution. Why is it so impactful here? To get some insights, look into the flame graph:
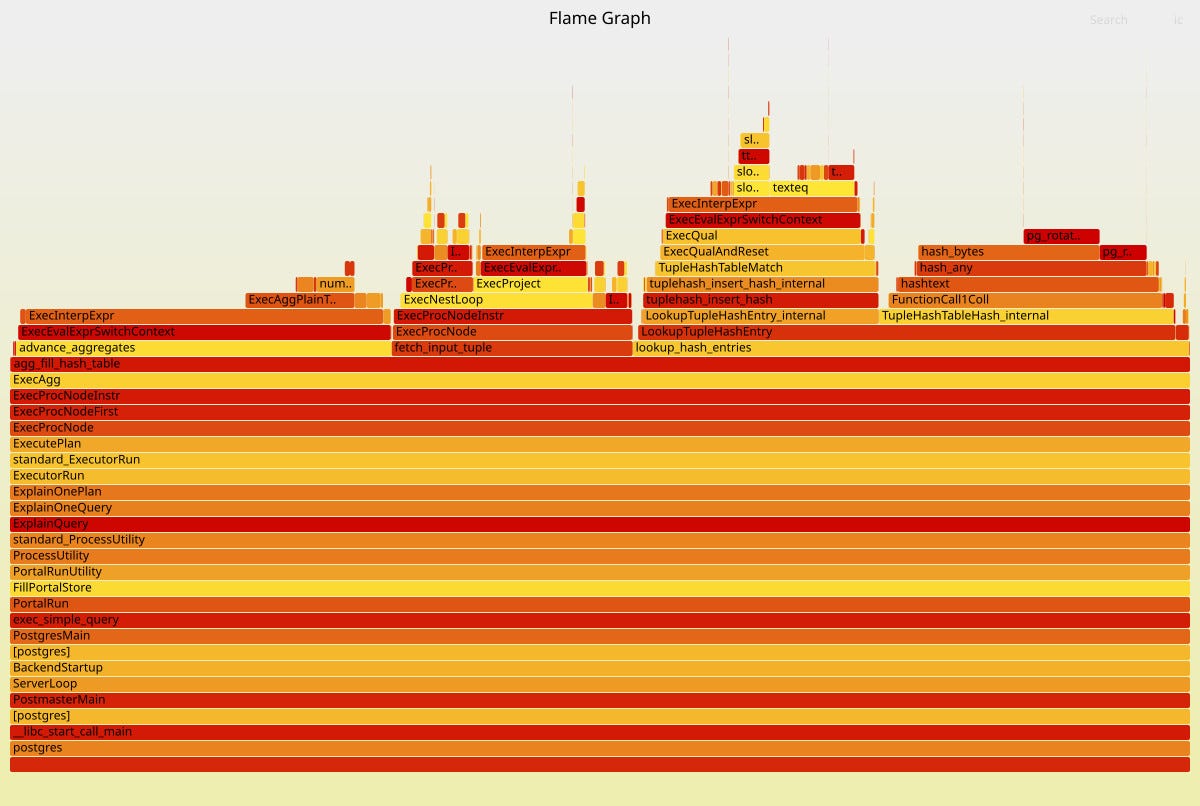
According to this graph, Postgres spends a lot of time generating hash values—the hashtext() routine—and comparing strings—the texteq().
Having a billion incoming tuples generated by the JOIN operation, the query is grouping them into 21 thousand groups. That means we have around 7E4 tuples in each group - lots of duplicates! The second part of this enigma is in the type of columns - all four columns have text type.
Look into the statistics over these columns:
SELECT a.attname,s.stadistinct,s.stanullfrac,s.stawidth
FROM pg_statistic s, pg_attribute a
WHERE
starelid=16395 AND
starelid=attrelid AND
s.staattnum=a.attnum AND
a.attname IN ('x1', 'x2', 'x3', 'x4');
attname | stadistinct | stanullfrac | stawidth
---------------+-------------+---------------+----------
x1 | 7 | 0 | 72
x2 | 3574 | 0 | 72
x3 | 6 | 0.00033333333 | 72
x4 | 3 | 0 | 50Because of duplicates, you can see that almost all comparisons in the first column, ‘x1’, will need a second comparison in ‘x2’. Moreover, each column is quite a long string, and to generate a hash or identify a duplicate, we should pass through around 300 bytes on average. Remember that hash aggregation make at least two computational operations for each incoming tuple - hash generation and string comparison. Recalling a billion incoming tuples - it may be a tremendous job and the reason for such a long time to group! In the absence of another obvious way to speed grouping operation, my main conjecture of MSSQL's impressive execution is the utilisation of parallelism.
Summarising that, I see two advantages: join algorithm selection and parallelism.
Parallelism
According to the documentation, MSSQL has implemented multithreaded parallelism to speed up groupings. As I can imagine, it is not easy to execute any aggregate in parallel mode, but trivial grouping by hash can be done in a highly parallel manner. Currently, when most of the data is generated in memory, it looks ideal for lightweight horizontal scalability codes.
PostgreSQL has parallel workers for such cases. However, being implemented as a process, it is a heavy tool. Postgres usually utilises 2-3 processes in a single query, parallelising the whole query subtree. What’s more, the process model and specifics of temporary table implementation don’t allow the use of parallel workers here.
To estimate how helpful parallel workers could be here, I have made tables persistent and forced many parallel workers. Forcing multiple parallel workers seems a bit tricky - you must reduce parallel startup and tuple costs. At the same time, you should reduce the min_parallel_table_scan_size and remember the max_parallel_workers GUC. The final configuration looks like this:
SET max_parallel_workers = 64;
SET max_parallel_workers_per_gather = 16;
SET parallel_setup_cost = 0.001;
SET parallel_tuple_cost = 0.0001;
SET min_parallel_table_scan_size = 0;And we are getting more comparable numbers on PostgreSQL:
Finalize HashAggregate (actual time=416s)
Group Key: t1.x1, t1.x2, t1.x3, t1.x4
-> Gather (actual time=416s)
Workers Launched: 9
-> Partial HashAggregate (actual time=416s)
Group Key: t1.x1, t1.x2, t1.x3, t1.x4
-> Nested Loop (actual time=68s)
-> Parallel Seq Scan on t1 (actual time=0.08s)
-> Index Scan using t2_idx on t2 (actual time=0.04)
Index Cond: t2.x1 = t1.x1 AND t2.x2 = t1.x2
Filter: t2.x3 = t1.x3 AND t2.x4 = t1.x4)
Rows Removed by Filter: 0
Execution Time: 416.5sAs you can see, the parallel workers’ technique helps. Its drawback is the rigidity of the process model. We should resolve issues with temporary tables and possibly show stoppers downstairs in the plan (volatile functions in selection filters, for example), which can lead to the rejection of parallel workers. The thread model, used locally in the grouping node, looks more flexible. Maybe ponder about a custom aggregate implemented in the multi-threading model. That's a good reason to start a GSoC project next year!
Multi-clause selectivity estimation
This case also represents one frequent problem: multi-clause JOIN. Multi-clause means something like that:
t1.x1 = t2.x1 AND t1.x2 = t2.x2 AND ... AND t1.xN = t2.xNPostgreSQL estimates the selectivity of the whole clause by a selectivity estimation of each AND’ed expression separately - let’s denote them
Having these estimations, it calculates the total number of rows produced by this join:
As you can imagine, this formula tends to underestimate the number of tuples produced. So, providing a good estimation for a single join clause, PostgreSQL underestimates if the data model needs to join tables by many clauses.
Looking into the MSSQL documentation and the research, I found out that there are a lot of statistics that the DBMS gathers: statistics on an index definition, WHERE clause, custom-made statistics (analogue of the Postgres CREATE STATISTICS) but with an addition of multiple options. The most interesting options are sampling and the WHERE clause, which allows the scanning of only part of a table. MSSQL contains so many statistics that developers invented complicated methods for asynchronous updates of these statistics.
Related to our case, the composite join clause, containing equality expressions on four columns, is transformed (my conjecture) into a comparison between two rows, likewise:
ROW(t1.x1,t1.x2,t1.x3,t1.x4) = ROW(t2.x1,t2.x2,t2.x3,t2.x4)and distinct (or histogram) statistics on t1(x1,x2,x3,x4) and t2(x1,x2,x3,x4) as a whole, allows MSSQL to estimate the cardinality of the JOIN more precisely. Fortunately, the PostgreSQL community already comprehend the issue and working out the solution right now.
THE END.