
PostgreSQL Asymmetric Join technique as a Further Evolution of Partitionwise Join
Elaborating Partitionwise Join

Attention: It is designed like a technical report, explaining the feature in internal terms of PostgreSQL code. So, it can be hard for bystanders to read this text.
Description
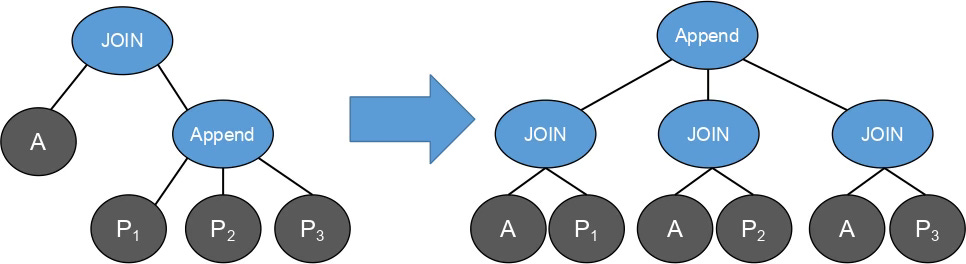
The Asymmetric Join (AJ) optimisation strategy introduces a novel approach to joining a partitioned relation (PR) and a non-partitioned relation (NR). Its uniqueness lies in individually connecting each partition with an NR and then merging the results using the APPEND operation. It looks like an essential evolution of the partitionwise join technique (PWJ) [4]. Although we haven’t seen any mention of this technique before — any links and references are welcome.
This strategy is a complete analogue of query rewriting using UNION ALL:
SELECT * FROM A JOIN partitioned B ON A.x=B.x; to:
(SELECT * FROM A JOIN B_1 ON A.x=B_1.x)
UNION ALL
(SELECT * FROM A JOIN B_1 ON A.x=B_2.x);The majority of the implementation for this strategy can be found in the ‘relnode.c’ and ‘joinrels.c’ files.
Advantages
It adds one more way to improve the efficiency of the Parallel Append.
Independent choice of join strategy for each partition.
The append does not have to combine large relations; it can sift most tuples out in the child join. This is also good if the join or target list has a heavy condition.
It allows the partitioning condition to be pushed directly into the inner, improving the filtering of the table scan procedure.
Reduces the hash table size of each particular child HashJoin and can ease the data skew problem.
Additional ways to partition pruning might also be found.
Further direction of FDW development towards shippable FOREIGN TABLES - as an analogy to shippable functions.
Flaws
The search space for plans is growing.
Limitations
inner of AJ is a table or subtree of a query that does not contain partitioned tables in its join tree.
outer doesn't have lateral references to the inner
Work principles
The code is similar to partitionwise_join and consists of changes in three parts of the optimiser code.
build_joinrel_partition_info
The first part of AJ is the initialisation of the partitioning properties of the RelOptInfo structure - part_scheme and part_exprs. AJ logic has been added to the end of the function. We only go to it if there is no way to apply PWJ. Since the optimiser will not call this function with the reverse order of inner and outer (for the partitionwise method, this does not make sense), here, for AJ, we must immediately check both options for placing inputs. Also, in the case of AJ, the inner does not have partitioning properties, and they are inherited from the outer. Also, here, the optimiser sets the consider_asymmetric_join flag - this only means that this joinrel can potentially be executed using the PWJ method and serve as an input for PWJ or AJ (only as an outer) at a higher level.
A significant difference introduced into the build_joinrel_partition_info routine is caused by the asymmetrical nature of this join technique. Let's say a join is made between two tables P1, P2 partitioned in the same scheme and one plain table T. If on the first attempt outer = (P1, P2), inner = (T), then PWJ cannot be built and AJ will be initialised. Then, on the next attempt, we have outer=(P1, T), inner = (P2), and the PWJ option cannot be considered. If the order of searching through combinations is different and the optimiser tries to construct (P1, T) JOIN (P2) first, then PWJ will be initialised, and following AJs between (P1, T) JOIN (P2) or (P1) JOIN (T, P2) will be rejected. For example, you can look at the following queries, which are also added to the regression tests in partition_join.sql:
EXPLAIN (COSTS OFF) -- PWJ on top
SELECT * from prt1 d1, unnest(array[3,4]) n, prt2 d2
WHERE d1.a = n AND d2.b = d1.a;
EXPLAIN (COSTS OFF) -- AJ on top
SELECT * from prt1 d1, prt2 d2, unnest(array[3,4]) n
WHERE d1.a = n AND d2.b = d1.a;Curiously, no matter which combination of inner and outer the optimiser tries to construct the joinrel - the part_scheme will be precisely the same pointer, and part_exprs must match up to the permutation of elements. This fact makes it possible to change the implementation in the future, eliminating dependency on the order of inner/outer combinations described above.
Also, we still have the open question: for the same joinrel, can different combinations of inner and outer allow AJ, but others can not? To detect that we added code to build_join_rel() that, having assertions enabled, checks that if the part_scheme for an already existing joinrel is not created, then after executing the build_joinrel_partition_info routine, it will not appear either. The mechanism does not consider all possible options but can help identify errors in autotests.
Another consequence of introducing AJ is that we must either save allowed combinations (inner, outer) or recheck the conditions of AJ in the try_asymmetric_partitionwise_join function. Logically, the first is cheaper.
One significant difference between the AJ logic and PWJ is that the consider_partitionwise_join flag is set gradually on RelOptInfo on different levels, starting with the lowest one - the partitioned table. Thus, a tree is built in which all elements have allowed properties. In the case of AJ, if you follow the same path, you will first need to check a lot (all sorts of tablesample, functionscan, etc.). In addition, there will be overhead even if there are no partitioned tables in the query. Therefore, in this implementation, build_joinrel_partition_info checks and sets AJ properties for the request subtree.
Checking all entries and subtree clauses in each combination is too expensive. Might it be better to invent a safe_for_asymmetric_join flag? Then, it will only be necessary to check the current RelOptInfo and the flags of the underlying ones. It would also be closer to PWJ implementation.
try_asymmetric_partitionwise_join
It is called in populate_joinrel_with_paths immediately after try_partitionwise_join. Since the caller is not expected to test for different ordering for the inputs, we must do this ourselves, given that the jointype may not allow us to swap the sides - this needs to be looked into carefully - since logically, we can swap the inner and outer sides by replacing, for example, the jointype from LEFT OUTER JOIN to RIGHT OUTER JOIN. However, is it technically simple and reasonable to accomplish? - It is an open question. In any case, the first step should be a demo query showing the limitation of our optimisation resulting from this section of code.
Here, we just double-check on the inner for AJ's correctness at the moment of building child joinrel.
Next, we initialise the RelOptInfo fields associated with partitioning: boundinfo, nparts, part_rels. If the fields are already initialised, then we simply check the identity of the partitioning scheme:
Assert(joinrel->nparts == prel->nparts && joinrel->part_rels != NULL);Here, I have a question that needs to be checked (see doubt No. 3).
Next, if everything is okay, we go through each partition from the outer and build a join with the inner. The tricky point here is replacing references to the relid of a partitioned table with the relid of its partition.
Next, we call populate_joinrel_with_paths and add paths to the child joinrel's pathlist for the combination of inner/outer.
generate_partitionwise_join_paths
Here, we collect all living part_rels of a given rel (recursively) and build APPEND, thus finishing the construction of partitionwise paths. The changes are minimal since, from the point of view of this function, the partition-related RelOptInfo fields for AJ and PWJ are identical. We just need to fix some consistency checks.
Reparameterisation
An important feature that interacts with AJ is reparameterisation (see the Parameterised NestLoop technique). A parameterised expression can refer to the inner side of some AJ, which can be inside the outer side of the parameterised NestLoop (PNL). Each path in the AJ’s child join may refer to the same underlying path on the inner side. Because of that, reparameterisation, altering such a path, must make a private copy beforehand.
To process it correctly, we introduced the is_asymmetric_join function, which detects a situation when the path is an asymmetric join, and it causes the replacement of relids in a flat copy of the path. The AJ criterion is the following: one of the inputs is a partition, and the other is a baserel or joinrel. Here, we may capture some extra cases, but copying instead of in-place changing will not worsen things; it would just waste more memory.
Doubts
It's still not obvious that we are checking the inner subtree entirely and correctly. What if the join clause contains a volatile function?
Also, we still haven't figured out how to expand the root->simple_*** array. Without this, we don't have native PostgreSQL core integration. See [3] for the reason.
The AJ & PWJ scheme is such that AJ, applied many times to the same joinrel with different inner/outer combinations, does not seem to lead to different partitioning schemes. But can one plain relation cause partition pruning differently than another combination of plain and partitioned relations? Could this cause the pruning of different part_rels[i]? And how can this affect the construction of the plan?
References
Current pgsql-hackers thread.
Current version can be found in this branch of my GitHub repository.
https://www.postgresql.org/message-id/CAExHW5vOGLD5MUW2tMTYR8pSjcT67%2BRVRyDy99fUSCKsdBELaA%40mail.gmail.com
Partition-wise joins: "divide and conquer" for joins between partitioned table