
Probing indexes to survive data skew in Postgres
An attempt to respond the data skew issue in Postgres planner

This is the story of an unexpected challenge I encountered and a tiny but fearless response to address the Postgres optimiser underestimations caused by a data skew, miss in statistics or inconsistency between statistics and the data. The journey began with a user's complaint on query performance, which had quite unusual anamnesis.
The problem was with only one analytical query executed regularly by the schedule. For one of the involved tables, the query EXPLAIN had indicated a single tuple scan estimation, but the executor ended up fetching four million tuples from the disk. This unexpected turn of events led Postgres to choose parameterised NestLoop + Index Scans on each side of the join, causing the query to execute two orders of magnitude longer than with an optimal query plan. However, after executing the ANALYZE command, estimations became correct, and the query was executed fast enough.
Problem Analysis
The problematic table was a huge one and contained billions of rows. The user would load data in large batches over the weekends and immediately run the troubling query to identify new trends, comparing the fresh data with the existing data. One of the columns in the data was something like the current timestamp, which indicated the time of addition to the database, and it was unique for the whole batch. So, I immediately suspected that the user's data insertion pattern was the reason impacting query performance — something in statistics.
After discovery, I found that the source of errors was the estimation of trivial filters like 'x=N', where N had a massive number of duplicates in the table's column. Right after bulk insertion into the table, this filter was estimated by the stadistinct number. On the ANALYZE execution, this value was detected as a 'most common' value; its selectivity was saved in statistics, and at the subsequent query execution, this filter was estimated precisely by the MCV statistic.
Let's briefly dip into the logic of the equality filter selectivity to understand this behaviour. See the script, generating a table with highly skewed value distribution:
CREATE EXTENSION tablefunc;
CREATE TABLE norm_test AS
SELECT abs(r::integer) AS val
FROM normal_rand(1E7::integer, 5.::float8, 300.::float8) AS r;
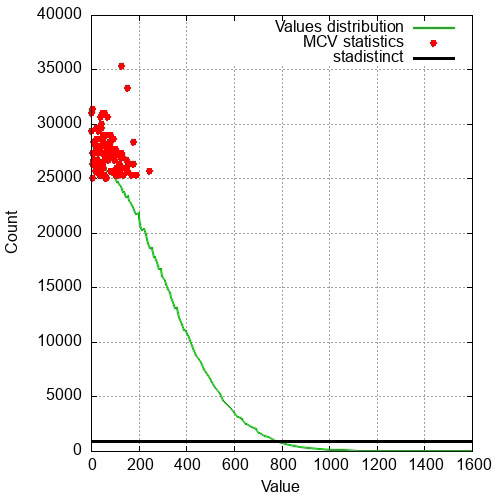
ANALYZE norm_test;Let's examine the statistics below for the column 'val'. The green curve shows the actual distribution of values in the column from 1 to 1600; the red dots are the most common values — they cover the top of the graph. The black line shows this column's number of distinct values (943).
Let's execute some simple scan SQL queries:
-- Involve MCV statistics ('5' inside the MCV stat)
EXPLAIN ANALYZE SELECT * FROM norm_test WHERE val = 5;
Gather (rows=27333 width=4) (rows=26416 loops=1)
-> Parallel Seq Scan on norm_test
Filter: (val = 5)
-- Frequent value but out of MCV
EXPLAIN ANALYZE SELECT * FROM norm_test WHERE val = 10;
Gather (rows=8614) (actual rows=26583)
-> Parallel Seq Scan on norm_test (rows=3589) (actual rows=8861)
Filter: (val = 10)
-- Rare value
EXPLAIN ANALYZE SELECT * FROM norm_test WHERE val = 10000;
Gather (rows=8614 width=4) (rows=0 loops=1)
-> Parallel Seq Scan on norm_test
Filter: (val = 10000)As you can see, the best situation is when the value fits MCV, another way Postgres estimates the cardinality of the filter according to the formula:
I.e., it excludes from the whole number of tuples common values and divides it by the number of remaining ndistincts (see var_eq_const for details). It looks like a single prediction for any other value outside MCV. But what if almost all of the values are MCV? Let's check it:
-- Add frequent values which are most of the data
CREATE TABLE norm_test1 AS SELECT gs % 100 AS val
FROM generate_series(1,1E7) AS gs;
-- Add some rare values
INSERT INTO norm_test1 (val) SELECT gs
FROM generate_series(101,105) AS gs;
VACUUM ANALYZE norm_test1;
ALTER TABLE norm_test1 SET (autovacuum_enabled = 'false');
-- Batch insertion of duplicates
INSERT INTO norm_test1 (val) SELECT 100 FROM generate_series(1,1E5);
EXPLAIN ANALYZE SELECT val FROM norm_test1 WHERE val = 100;
Gather (rows=1) (actual rows=100000)
-> Parallel Seq Scan on norm_test1
Filter: (val = '100'::numeric)As you can see, we got precisely the estimation described in the issue above. After such a long explanation, how should Postgres handle such a scenario?
Upon investigation, I discovered that Postgres has already implemented a solution: the 'index probing' technique for the inequality operator (like '<' or '>'). This technique employs the histogram to calculate the number of bins that fall into the inequality filter boundaries.
After reviewing the git history of this feature and the discussion, I realised that it suffers from performance issues. So, does it make sense to use the same trick for an equality operator? Would it be suitable for some sophisticated analytical queries? Let's try to implement this feature and assess the overhead afterwards with benchmarks.
Implementation Description
You can see the working implementation in the branch of my GitHub repository. The idea is as follows: If we can't use MCV for an equality expression and some empirical condition detects that distinct estimation can be suspicious, let's try to find an index that covers this column. With such an index, call the AM index_getbitmap routine to estimate the number of tuples that satisfy the condition. Picking the NonVacuumableSnapshot will guarantee an upper-bound estimation.
The index_getbitmap routine collects only the TIDs of tuples, not the tuples themselves. Of course, this estimation process can be time-consuming for multiple tuples. The better option could be to make two IndexScan operations - forward and backward scan on the target const value - to find lower and higher bounds and roughly estimate the number of tuples by the number of pages between these two values. But as I can see, the AM interface in Postgres is still not ready to provide the caller with information on a couple (page, offset) of the first tuple found.
One consideration that relieves the aftereffects of this approach on performance is that calling index_getbitmap pulls index pages from the disk into memory that can be reused during query execution.
The crucial point is the condition when we involve the index probing approach. There is room for improvisation, but being short on time, I just invented a trivial one: looking into the histogram's bounds and seeing if the value fits the boundaries. If it is out of the histogram's coverage, we suppose that statistics is untrusted and probe an index.
Benchmarking
To find the worst case, I employed pgbench, as usual. The benchmarking script looks like the following:
pgbench -i -s 10
psql -c "ALTER TABLE pgbench_accounts
DROP CONSTRAINT pgbench_accounts_pkey;"
psql -c "ALTER TABLE pgbench_branches
DROP CONSTRAINT pgbench_branches_pkey;"
psql -c "ALTER TABLE pgbench_tellers
DROP CONSTRAINT pgbench_tellers_pkey;"
psql -c "CREATE INDEX ON pgbench_accounts(aid);"
psql -c "CREATE INDEX ON pgbench_branches(bid);"
psql -c "CREATE INDEX ON pgbench_tellers(tid);"
pgbench -c 5 -j 5 -T 180 -P 3 -f test_s.pgbHere, we deleted unique indexes and created non-unique ones because the optimiser uses them to return single tuple estimation. Query set contained only single SELECT quite frequently coming with the constant out of the histogram boundaries:
\set aid random(-5000000 * :scale, 5000000 * :scale)
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;Analysing the results of this benchmark, I observed a 5% overhead on touching histogram statistics and an additional 5-6% on probing indexes. It looks like a huge overhead, but the code is just a simple sketch. Who anticipated an ideal result?
That's it for today. In conclusion, I must emphasise that this approach not only worsens performance but also holds great potential for application in specific, narrow cases. The question is, might we effectively limit its involvement using an empirical formula? May a global or table-only GUC be a lifesaver in that case?
In unlucky situations where data skews make estimations so bad that they cause a performance slump of a degree of magnitude, we are left with no tools except the schema change. In such cases, this feature can be a handy solution.
THE END.
August 11, 2024. Paris, France
Yes, I have always been worried that common values that are not in the MCV set could produce inefficient optimizer results. Good idea on checking the histogram or index. As you said, the big challenge is knowing when to check them. We might have the executor somehow detect this for later queries.