
Revising the Postgres Multi-master Concept
Does logical replication have hidden potential?

One of the ongoing challenges in database management systems (DBMS) is maintaining consistent data across multiple instances (nodes) that can independently accept client connections. If one node fails in such a system, the others must continue to operate without interruption - accepting connections and committing transactions without sacrificing consistency. An analogy for a single DBMS instance might be staying operational despite a RAM failure or intermittent access to multiple processor cores.
In this context, I would like to revisit the discussion about the Postgres-based multi-master problem, including its practical value, feasibility, and the technology stack that needs to be developed to address it. By narrowing the focus of the problem, we may be able to devise a solution that benefits the industry.
I spent several years developing the multi-master extension in the late 2010s until it became clear that the concept of essentially consistent multi-master replication had reached a dead end. Now, after taking a long break from working on replication, changing countries, residency, and companies, I am revisiting the Postgres-based multi-master idea to explore its practical applications.
First, I want to clarify the general use case for multi-master replication and highlight its potential benefits. Apparently, any technology must balance its capabilities with the needs it aims to address. Let's explore this balance within the context of multi-master replication.
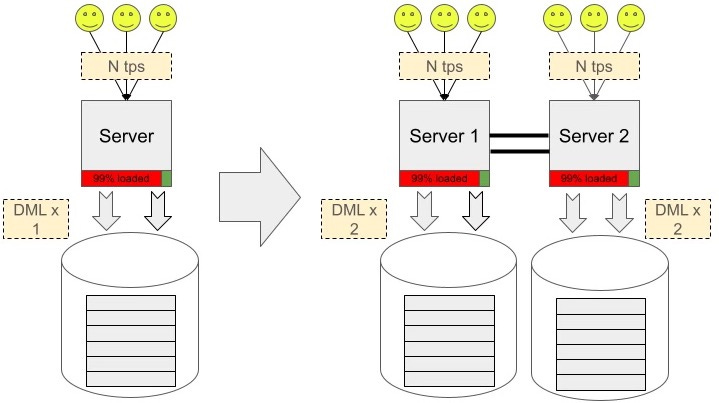
Typically, clients consider a multi-master solution when they hit a limit in connection counts for their OLTP workloads. They often have a large number of clients, an N transaction-per-second (TPS) workload, and a single database. They envision a solution that involves adding another identical server, setting up active-active replication, and doubling their workload.
Sometimes, a client has a distributed application that requires a stable connection to the database across different geographic locations. At other times, clients simply desire a reliable automatic failover. A less common request, though still valuable, is to provide an online upgrade or to enable the detachment of a node for maintenance. Additionally, some clients may request an extra master node that has warmed-up caches and a storage state that closely resembles the production environment, allowing it to be used for testing and benchmarking. In summary, there are numerous tasks that can be requested, but what can realistically be achieved?
It's important to remember that active-active replication in PostgreSQL is currently only feasible with logical replication, which denotes network latency and additional server load from decoding, walsender, and so on. Network latency also immediately arises - we need to wait for confirmation from the remote node that the transaction was successfully applied, right? Therefore, the idea of scaling the write load for the general case of 100% replication immediately encounters the fact that each server will be required to write not only its own changes, but also changes from other instances (see the figure above). That isn't a problem for massive queries with bushy SELECTs, but a multi-master query is more likely to be used by clients with pure OLTP and very simple DML.
We face a similar challenge when trying to provide each copy of the distributed application with a nearby database instance. If the application's connection to the remote database is weak, then the connection between the two DBMS instances will also be unstable. As a result, waiting for confirmation of a successful transaction commit on the remote node can lead to significant delays.
Complex situations can also occur when a replication update tries to overwrite the same table row that has been updated locally. Such an event can happen because we have no guarantee that the snapshots of the transactions that caused these conflicting changes are consistent across DBMS instances. This raises the question: whose change should be applied, and whose should be rolled back? Does a single row change within the transaction logic need to take into account the competing change for it to be valid?
The autofailover case is relatively straightforward, but something still needs to be done to make such a configuration effective: after all, if all instances can write, then a transaction commit must be accompanied by a supplemental message ensuring that the transaction is written at each instance. Otherwise, it could happen that if node Nx crashes, some of its transactions will be written to the database on node Ny, but will not be committed to (or will be rolled back in) the database of node Nz. So, how do you fix this situation except by sending the entire configuration to recovery?
So, the concept of multi-master replication can be questionable, particularly for those seeking to accelerate OLTP workload. So, why would anyone need it? Let's begin by examining the underlying technology: logical replication.
I see two significant advantages to logical replication. First, it enables highly selective data replication, allowing you to pick only specific tables. Additionally, for each table, you can set up filters with replication conditions that let you easily skip individual records or entire transactions right at the outset of the replication process during the decoding phase. This feature provides a highly granular mechanism for selecting specific data that should be synchronised with a remote system.
The second notable advantage is the high-level nature of the mechanism. This type of replication occurs at the level of relational algebra, which means you can abstract away the complexities of physical storage.
What amazing benefits come with a high level of abstraction? Imagine the possibilities! You can customise different sets of indexes on synchronised nodes, which significantly reduces DML overhead and allows you to route queries based on where execution can be most effective. For example, you could focus on loading one instance with brief UPDATE/DELETE queries on primary keys, while reserving another instance for larger subqueries or INSERTs that usually don't conflict with updates. You could even mix it up by using a traditional Postgres heap on one instance and a column storage on another! The creativity here knows no bounds when it comes to the potential of your replication protocol.
Now that we have outlined the benefits of logical replication, let's consider a use case that can be effectively implemented using a multi-master configuration.
To begin, we will set aside concerns related to upgrades, maintenance, and failovers. The most apparent use case is for supporting a geo-distributed application. By categorising the data in the database into three types - critically important general data, general data that is changed on only one side, and purely local data - we can leverage the advantages of this setup (see figure).
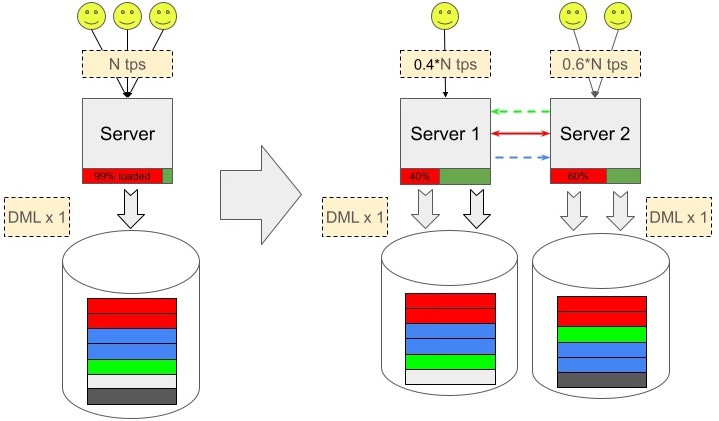
Here, the red rectangle denotes data that must be reliably synchronised between instances. The green and blue denote data that doesn't require immediate synchronisation and should be accessible to the remote instance in read-only mode. The grey denotes purely local data.
By designing the database schema to categorise data by replication method, we can even reduce the database size on a specific instance by avoiding the transmission of local data to remote nodes. Furthermore, plenty of data can be replicated asynchronously in one direction, avoiding the overhead of waiting for the remote end to confirm a commit. Only critical data requires strict synchronisation, using mechanisms such as synchronous commit, 2PC, and at least REPEATABLE READ isolation level, which enormously raises the commit time of such a transaction and increases the risk of rollback due to conflicts.
What is an example of this use case? To be honest, I don't have any experience with customer installations, so I can only imagine how it might work hypothetically. I envision an international company that needs to separate employee data and fiscal metrics on servers located in each country, which seems to be a common requirement these days. For analytical purposes, this data could be made accessible externally, similar to how key values can filter replicated data.
The company's employee table could be divided, replicating names, positions, salaries, and other relevant information across all database instances. Sensitive identifiers, such as social security numbers or passport numbers, could be kept in a separate local table to maintain privacy.
In principle, if updates to local or asynchronously replicated data dominate, it may be possible to achieve the desired scalability for writing operations (sounds wicked, but who knows...).
Drawing from my experience in rocket science, I've developed the habit of qualitatively evaluating the effects of the phenomena being studied beforehand. Let's estimate the percentage of the database that can be replicated in active-active mode without potentially degrading performance. For simplicity, let's assume there are two company branches located on different continents, and consider the following configuration options: (1) one server, or (2) two servers operating in multi-master mode, where access will always be local (as illustrated in the figure below).
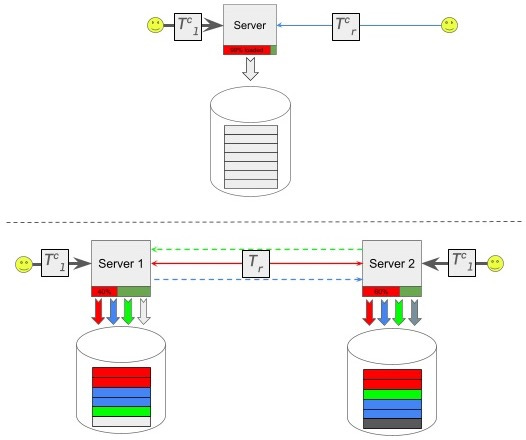
Let's introduce some notations. Please refer to the figure above for further clarification:
Tl - transaction execution time in a DBMS backend, ms.
Tcl - network round-trip time between DBMS and local application, ms.$
Tcr - network round-trip time between DBMS and remote application, ms.
Tr - extra time to ensure that the transaction is successfully committed across the DBMS cluster, ms.
Xl - fraction of local connections.
N - fraction of transactions that are OK with asynchronous replication guarantees.
For a single server holding all the connections we have:
Active-active replication has the following formula:
Now, let's determine appropriate numbers for our formulas. We'll assume a 50% share for local connections (Xl = 0.5). Drawing from my experience living in Asia and connecting to resources in Europe, we can use the following figures as a reference:
In this context, Tcl and Tcr are the time of one round-trip. In contrast, confirming a remote commit (Tr) usually requires at least two round-trips: in the 2PC protocol, the PREPARE STATEMENT command should first be executed, waiting for the changes to be successfully replicated and all the resources necessary for the commit to be reserved, and then the COMMIT command should be issued.
Based on these timing considerations, we can calculate the following:
Now, let's imagine that the number of remote connections has grown by 80%:
What if we need to ensure full synchronous 2PC synchronisation of the entire database? Let's do the math:
These numbers indicate a performance loss of approximately 2.5 times, even in the most optimistic scenario. While it's not particularly encouraging, may it be sufficient for some applications?
This rough calculation suggests that if approximately 25% of DML transactions require remote confirmation, the multi-master system has a chance to stay with the same writing performance. If the majority of traffic originates from remote regions, the proportion of reliably replicated data could increase to 40%. However, for a more conservative estimate, let's stick with N = 25%. This approach also eases some of the load on the disk subsystem, locks, and other resources, allowing them to be used for local operations such as VACUUM or read-only queries. There appears to be a grain of truth in that, doesn't it?
On the other hand, replication, even if asynchronous, must be able to keep up with the commit flow. If the total time required for local transaction execution is 15 ms, and the one-way delay to the remote server is 75 ms, then even without waiting for confirmation from the remote side, a queue of changes for replication will still accumulate in a sequential scenario.
25% of the DML in our computation is committed with remote confirmation, leaving 75% to be replicated. 75 ms * 0.75 = 56 ms. To address the disparity between the rate of local commits and the speed of data transfer to the remote server, we must utilise the bandwidth by sending and receiving data on the remote server in parallel (i.e., parallel replication is required). In our rough model, it turns out that four threads are sufficient to transfer changes. Considering the freed-up server resources (resulting from distributing connections between instances), this seems quite realistic.
So, the bottom line is that by distributing data geographically in multi-master mode, we can theoretically expect comparable transaction handling speed. This also reduces the number of backends and resource consumption on each server. These resources can be freed up for system processes and various analytics. Let's not forget the ability to optimise indexes, storage, and other attributes of physical data placement independently on each system node. An additional benefit is that in the event of a connection failure, each subnet can be temporarily maintained with the expectation that, upon recovery, a conflict resolution strategy will restore the database's integrity.
It's easy to imagine an application for such a scenario with a complete network breakdown - for example, a database for a hospital network in a region with complex terrain and climate. The medical records database must be shared, but a single client is unlikely to be served by two different hospitals within a short period of time, making conflicts in critical data quite rare.
Taking all of the above into account, a viable multi-master solution should implement the following set of technologies:
Replication sets – to classify data for replication, providing separate synchronous and asynchronous replication.
Replication type dependency detection - check that synchronously replicated tables don't refer to asynchronously replicated tables.
Remote commit confirmation (similar to 2PC).
A distributed consensus protocol for determining a healthy subset of nodes and fencing failed nodes in 3+ configurations.
Parallel replication – parallelising both DML sending and application on the remote side.
Automatic Conflict Resolution.
Let's not overlook the importance of automatic failover and the capability to hot-swap hardware without any downtime. Currently, the concept of alternative physical storage arrangements still sounds a little wild, so I'm excluding it from our discussion for now. However, if we gain more experience with successful multi-master implementations, this option might eventually become the preferred approach.
That's all for now. This post is meant to spark discussion, so please feel free to share your thoughts in the comments or through any other method you prefer.
THE END.
October 18, 2025, Madrid, Spain.