
Whose optimisation is better?
How to compare the quality of SQL query plans in PostgreSQL

That happened one long and warm Thai evening when I read another paper about the re-optimisation technique in which the authors used Postgres as a base for implementation. Since I had nearly finished with the WIP patch aiming to do the same stuff in the Postgres fork, I immediately began comparing our algorithms using the paper's experimental data as a reference. However, I quickly realised that neither my code nor even the standard Postgres instance bore any resemblance to the paper's figures.
The execution time measurements they provided differed significantly due to unclear details regarding the experimental setup and instance settings. I had often encountered research reports that were almost impossible to reproduce, and the current case led me to discover how we could compare query plans and optimisation effectiveness using dimensionless criteria.
From a practical point of view, the DBMS that produces a higher TPS is more efficient. However, sometimes, we need to design a system that does not yet exist or make a behaviour forecast for loads that have not yet arrived. In this case, we need a parameter to analyse a query plan or compare a pair of plans qualitatively. This post discusses one such parameter - the number of data pages read.
It hardly needs to be said that the 'performance evaluation' section of research is crucial for applied software developers, as it justifies the time spent reading the preceding text. This section must also ensure the repeatability of results and allow for independent analysis. For instance, a similarity theory has been developed in fields like hydrodynamics and heat engineering that enables researchers to present experimental results in dimensionless quantities, such as the Nusselt, Prandtl, and Reynolds numbers. Researchers can reasonably compare the results obtained by reproducing experiments under slightly different conditions.
I have not yet seen anything like this in database systems. The section devoted to testing usually briefly describes the hardware and software parts and graphs. The main parameter under study is the query execution time or TPS (transactions-per-second).
This approach appears to be the only viable method when comparing different DBMSes and making decisions regarding what system to use in production. However, it's important to note that query execution time is influenced by multiple factors, including server settings, caching algorithms, the choice of query plan, and parallelism...
Let's consider the scenario where we are developing a new query optimisation method and want to compare its performance with a previously published method. We have graphs showing query execution times (see, for example, here or there), along with a brief description of our testing platform. However, we encounter discrepancies between our results and those from published studies due to multiple unknown factors. To address this, we need a measurable parameter that can eliminate the influence of other DBMS subsystems, making our analysis more portable and accessible. I believe that developers working, for example, on a new storage system would also appreciate the opportunity to remove the optimiser's impact from their benchmarks.
When attempting to reproduce the experiments described in articles or to compare my method with the one proposed by authors, I often find that the uncertainty of the commonly accepted measurement of execution time is too high to draw conclusive judgments. This measure primarily reflects the efficiency of the code under specific operating conditions rather than the quality of the discovered query plan. Execution time is a highly variable characteristic; even when running the same test consistently on the same machine and instance, there can be a significant variation in execution times.
For instance, I've conducted ten consecutive runs of all 113 Join Order Benchmark (JOB) tests, and I've observed a typical spread in execution time of up to 50% on my desktop (see the picture below) - even under optimal conditions with all experiment parameters are meticulously controlled. This raises a crucial question: how much deviation might an external researcher encounter if they attempt to repeat the experiment, and how should they analyse the results?

One more concern is how to compare query plans executed with varying numbers of parallel workers. Using multiple workers on a test machine can yield positive results; however, parallelism can sometimes be counterproductive in a production with hundreds of competing backends. Therefore, is it best to seek a more meaningful criterion for evaluation?
In my specific area of query optimisation, execution time often seems like a redundant metric. It may be more beneficial to adopt a more specific characteristic to compare different optimisation approaches or to assess the impact of a new transformation within the PostgreSQL optimiser. Such a metric should include only factors that the optimiser may consider during the planning process.
From the perspective of a DBMS, the primary operations involve data manipulation. Thus, it would be natural to select the number of operations performed on table rows during query execution, taking into account the number of attributes in each row. Minimising this parameter would indicate the efficiency of the chosen query plan. However, collecting such statistics can be challenging. Therefore, we should aim to identify a slightly less precise but more easily obtainable parameter.
For example, DBAs often use the number of pages read as a parameter. In this context, a page refers to a buffer cache page or a table data block stored on disk. It is unnecessary to differentiate between the pages that fit in the RAM buffer and those on disk, as this distinction provides redundant information that pertains more to the page eviction strategy and disk operation than to the optimal plan identified.
For our purposes, it is sufficient to sum these values mechanically. We also need to consider the pages from the temporary disk cache used by sorting, hashing, and other algorithms for placing rows that did not fit in memory. It is important to note that the same page may need to be counted twice. We access a page once during sequential row scanning to read its tuples. However, when rescanning—such as in an inner NestLoop join—we reread the data and must account for each page again. PostgreSQL already has the necessary infrastructure for measuring the number of pages read, provided by the pg_stat_statements extension. My approach is as follows: before executing each benchmark query, I run the command SELECT pg_stat_statements_reset() and then retrieve the statistics using the following query:
SELECT
shared_blks_hit+shared_blks_read+local_blks_hit+local_blks_read+
temp_blks_read AS blocks, total_exec_time::integer AS exec_time
FROM pg_stat_statements
WHERE query NOT LIKE '%pg_stat_statements_reset%';How reliable is this metric? In the same experiment mentioned above, all ten runs of the JOB test demonstrated negligible deviation in the number of pages for each query throughout the iterations:

There is a deviation of only a few pages, and while even a minor discrepancy like this should typically be examined, it seems to be more of an artifact resulting from service operations, such as accessing statistics and interactions among parallel workers. What can we infer from this indicator? Let's conduct a simple experiment. We will use one test query (10a.sql) and sequentially increase the number of workers involved in processing this query. The graph below illustrates how the query execution time and the number of data pages read change as we adjust the number of workers.
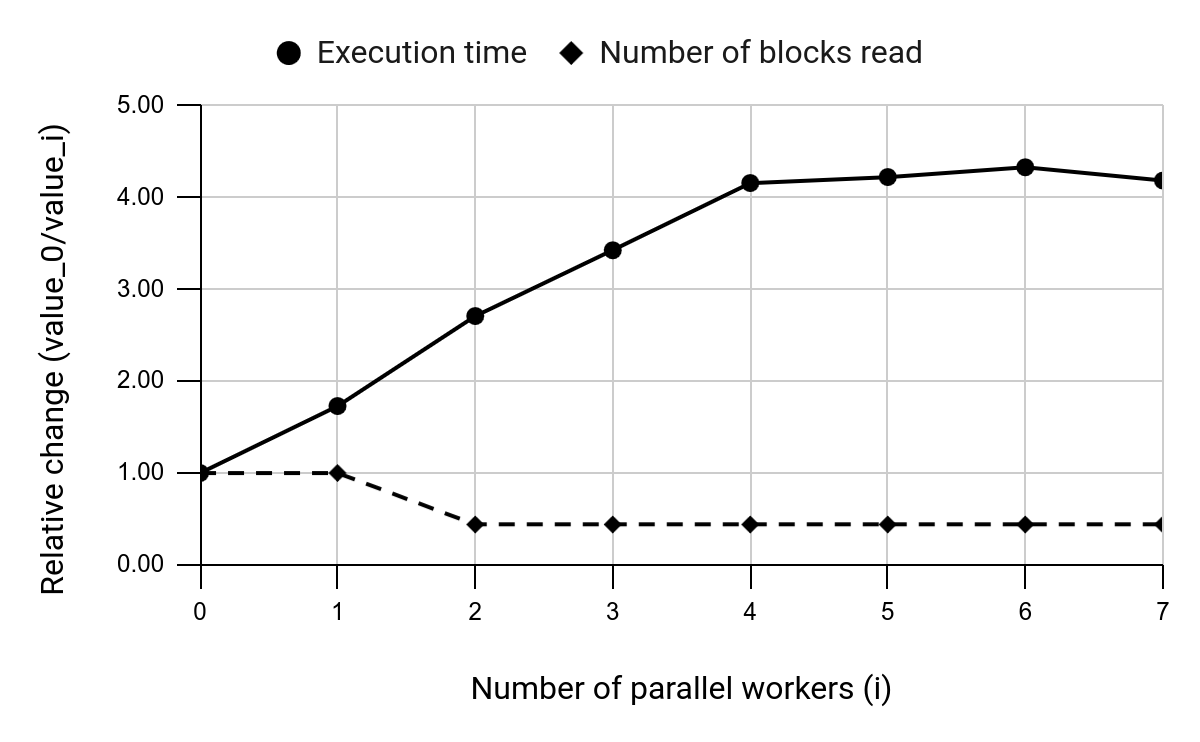
It is evident that while the query execution time may vary, the number of read data pages remains relatively constant. The number of pages only changes once when the number of workers increases from 1 to 2, resulting in a doubling of the read pages. An examination of the EXPLAIN output for these two cases reveals the reason behind this change: with 0 and 1 worker, out of six query joins, three were of the Nested Loop type, and three were Hash Joins. However, with two or more workers, the number of Nested Loop joins increases by one while the number of Hash Joins decreases. Thus, by analysing the number of read pages, we were able to identify a change in the query plan that was not apparent when considering execution time alone. Now, let's explore the effect of the AQO (Adaptive Query Optimization) extension of the PostgreSQL optimiser on JOB test queries.
We will execute each test query with AQO ten times in 'learn' mode. In this mode, AQO functions as a planner memory, storing the cardinality of each plan node (as well as the number of groups in the corresponding operators) at the end of execution. This information is then used during the planning stage, allowing the optimiser to reject overly optimistic plans. Given that the PostgreSQL optimiser tends to underestimate join cardinalities, this approach appears quite reasonable. The figure below (shown on a logarithmic scale) illustrates how the number of pages read changed concerning the first iteration, during which the optimiser lacks information about the cardinalities of the query plan nodes, the number of distinct values in the columns, etc. By the tenth iteration, almost all queries either improved this metric or remained unchanged. This suggests that the PostgreSQL optimiser may have quickly identified the best plan in the space of potential options or that our technique did not have the desired effect in these cases.

There are still six degraded queries remaining, and the number of pages read for these queries has increased compared to the first iteration. It's possible that there weren't enough iterations to effectively filter out non-optimal query plans. Therefore, let's increase the number of execution iterations to 30 and observe the results.
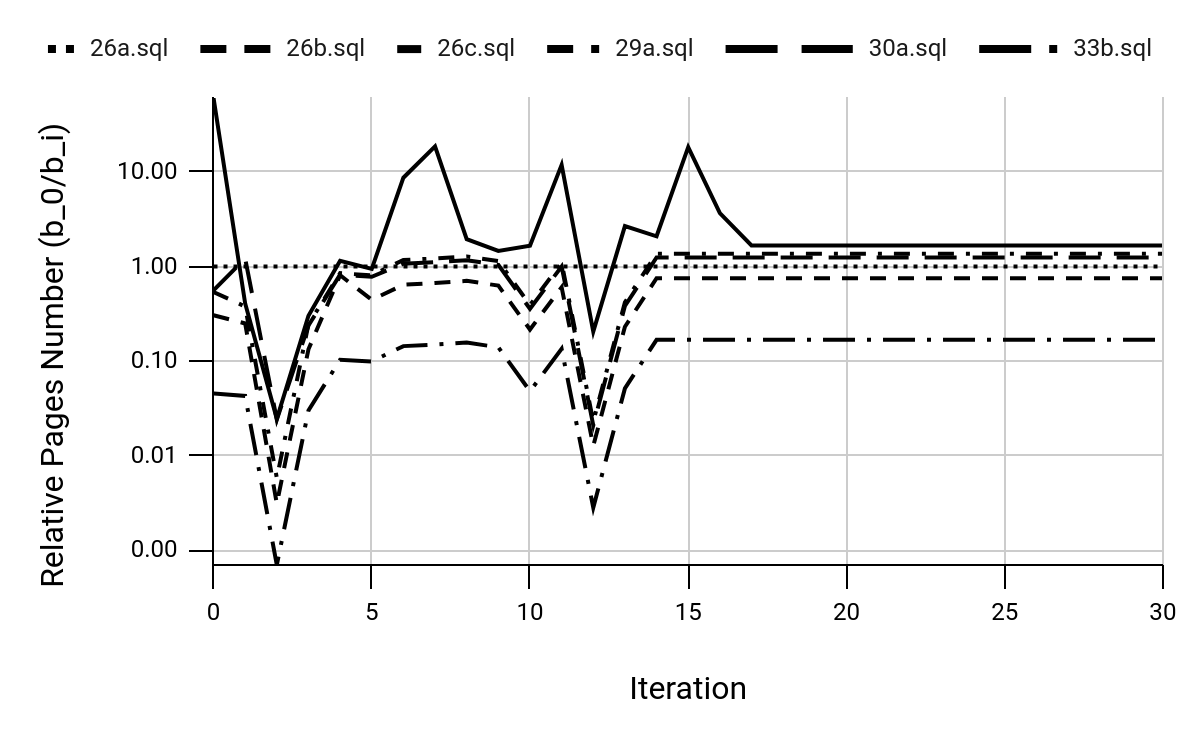
The figure above illustrates that the query plans have converged toward an optimal solution. Notably, two queries (26b and 33b) show an increase in the number of pages read compared to the zero iteration. Additionally, the query execution time has improved by 15-20%.
The explanations for these observations are as follows: the number of Nested Loops in the query plan has decreased by one, and the Hash Join, when constructing a hash table, scans the entire table and consequently increases the number of pages read. In contrast, the parallel Hash Join proves to be more time-efficient, leading to better query execution times. This suggests that the number of pages read is not an absolute criterion for determining query optimality. This criterion can help establish a starting point within a single DBMS, allowing for reproduced experiments in different software and hardware environments. It can also aid in comparing various optimisation methods and identifying effects that may be masked by unstable execution times.
Therefore, it may not be advisable to disregard execution time when publishing benchmark results. However, should the number of pages read to be included as well? Ultimately, by providing a graph showing the changes in the number of pages read during query execution, along with a test run script (refer to the above) and a link to the raw data, one can independently reproduce the experiment, calibrate it against the published data, conduct additional studies, or compare it with other methods under similar conditions. Isn’t that convenient?
That's it for today. The primary goal of this post is to highlight the problem of reproducibility of results and to encourage objective analysis of new methods in the field of DBMS. Should we seek additional criteria for evaluating test results? How effective is the criterion of the number of pages read for this purpose? Can this criterion be adapted to compare different yet similar query plans regarding DBMS architecture? Is it possible to normalise this criterion relative to the average number of tuples per page? I welcome any opinions and comments on these questions.
THE END.
January 18th, 2025. Pattaya, Thailand.
Thank you for the write up, it really is a frustrating problem with benchmarking data, not having a clear structure to repeat the experiments.