
Looking for hidden hurdles when Postgres face partitions
Does it find a good plan for a partitioned table as for a single one?

Preface
This post was initially intended to introduce my ‘one more Postgres thing' - a built-in fully transparent re-optimisation feature, which I'm really proud of. However, during benchmarking, I discovered that partitioning the table causes performance issues that are hard to tackle. So, let's see the origins of these issues and how PostgreSQL struggles with them.
Here, I do quite a simple thing: having the non-trivial benchmark, I just run it over a database with plain tables, do precisely the same thing over the database where all these tables are partitioned by HASH, and watch how it ends up.
When I finished writing the post, I found out that benchmarking data looked a bit boring. So, don’t hesitate to skip the main text and go to the conclusion.
Preliminary runs
The Join-Order Benchmark has some specifics that make it challenging to stabilise execution time through repeating executions. Processing many tables and most of their data makes query execution time intricately dependent on the shared buffer size and its filling. The frequent involvement of parallel workers further complicates the process, with the potential for one worker to start after a long delay, leading to performance slumps.
What’s more, it turned out that the ANALYZE command is not entirely stable on this benchmark's data, and I constantly observe that rebuilding a table statistic causes significant changes in estimations, followed by different query plans.
To manage these complexities, I used pg_prewarm for over 4GB shared buffers (all data size is about 8GB). We still can't pass statistics through the pg_upgrade process, although I feel it will be possible soon. So, I just analysed the tables one time after filling them with data. I passed all 113 benchmark queries ten times, wasting all the first run because of instability1. The scripts to create schemas, benchmarking scripts, and data can be found in the repository on GitHub.
To gauge the stability of the execution time, I conducted the benchmark over the schema with plain tables (see reference to the schema script). After a meticulous analysis of the results (see graphs for Postgres 15, 16 and 17), it becomes apparent that the dispersion of execution times of a query primarily falls within the range of -25% to +25%. With a few exceptions, the execution time consistently falls within the -50% to +50% range.
But comparing execution times of 15 with both 16 and 17, we see the constant shift for both newer versions:
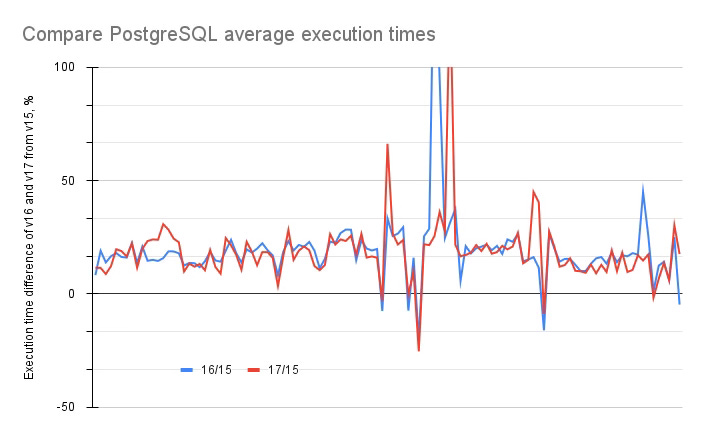
Everywhere on the graphs in this post, the term 'execution time difference' means the following (i - the number of a version: 16 or 17):
Despite some instability in the executions, as mentioned earlier, I observed a surprising decrease of about 17% in execution time for both the 16 and 17 versions. This unexpected change prompts the question: what’s happening here? A comparison of their query plans with v.15 might hold the answer.
A thorough checking of query plans has shown that v.15 uses parameterised NestLoop more frequently (388 times v/s 376 times in v.16 and 381 in v.17 - the latter prefers more Parallel Hash Join for a reason). Doing that, it chooses the Memoize node (39 times V/S 32 and 35 for newer versions) and IndexScan (342 times V/S 329 and 332) and, as a result, rarely uses SeqScan. That is the reason for the peaks you see on the graph.
In general, we can only conclude that something has changed in the PostgreSQL planner as well as the executor since v.16. In the planner, it is obviously related to the cost model. In the executor, I suppose something is in parallel execution machinery. These changes influenced execution, but it is hard to say how it could work in another case. I wonder if someone else would pass the same benchmark case and compare the numbers.
But for now, we have a 25% trustful range, and I want to see if the partitioning impacts performance and throws the execution time of queries out of this range.
Partitioning (2 partitions case)
Now, create a schema with the same tables and data, but split each table into two partitions by HASH (see schema). Fortunately, in this benchmark, each table has an ID field, so it was easy to choose a partitioning schema.
In my mind, replacing a plain table with the one partitioned by HASH into two partitions can influence planning time a bit but shouldn’t significantly change execution time: taking advantage of possible partition pruning, we add the only Append operation into the plan, which adds low overhead.
Okay, let’s pass through the benchmark and look into the numbers.
As you can see in the picture below, all three Postgres versions show us some performance degradation, around 40% on average. But specific queries degrade for 100% and more. Demonstrating such a stable shift should have some underlying reasons.
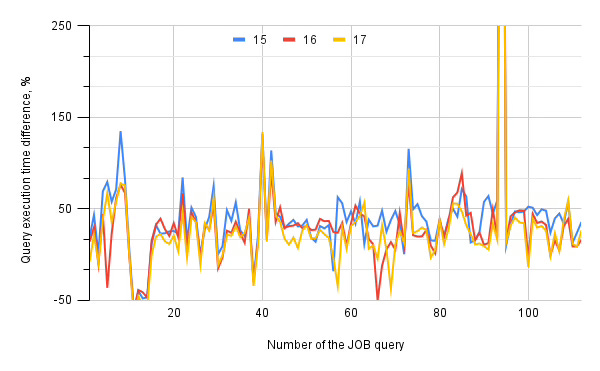
Comparing the benchmark's results for partitioned and non-partitioned PostgreSQL 17, I see nothing special: all queries executed in parallel, the choice of NestLoop decreased from 381 to 317 cases, and four MergeJoins compared to 1 for a plain-table run. The number of IndexScans has plummeted from 332 to 282. The number of Memoize choices is the same—32, which means PostgreSQL has stable decisions about parameterised joins with cached inner. But something still happens, and we need to discover it.
Let's choose the worst cases and compare their query plans to solve the mystery. I have chosen the following cases:
query 12a.sql - 135% degradation; 1b.sql - 134%; 1d.sql - 114%; 2a.sql - 116%; 33a.sql - 89%; 5a.sql - 972%.At first, I found out that Parallel Append constantly executes in more time than a single Parallel Seq Scan:
-> Parallel Append (actual time=9.643..155.768 rows=460012 loops=3)
-> Parallel Seq Scan on movie_info_idx_p2
(actual time=0.033..52.699 rows=230217 loops=3)
-> Parallel Seq Scan on movie_info_idx_p1
(actual time=14.431..97.858 rows=344692 loops=2)
-> Parallel Seq Scan on movie_info_idx
(actual time=0.027..65.034 rows=460012 loops=3)As you can see, it is about two times faster. Maybe we could say it is a page buffering problem, but I see it frequently through all the runs. Perhaps the reason here is lurking around the number of loops: in each Append, I see three loops for the first sibling and only two for the last. It looks like a bug in parallel workers’ utilisation. One more issue here is a long startup actual time - 9ms vs 0.027 for just two partitions!
The second issue is cost estimation. Look at this:
-> Parallel Append (cost=0.00..35107.72 rows=1933 width=8)
-> Parallel Seq Scan on movie_companies_p2 mc_2
(cost=0.00..17569.53 rows=1301 width=8)
Filter: ((note ~~ '%(theatrical)%'::text)
AND (note ~~ '%(France)%'::text))
...
-> Parallel Seq Scan on movie_companies mc
(cost=0.00..35097.06 rows=1677 width=8)
Filter: ((note ~~ '%(theatrical)%'::text)
AND (note ~~ '%(France)%'::text))This additional estimation error blows up estimations through the upper query plan's levels and (possibly) triggers the third source of degradation: in all cases, having chosen to scrutinise, I found out that on top-level JOIN, instead of parameterised NestLoop, which gradually reduced the number of tuples scanned from the big table, the optimiser has chosen ParallelHashJoin, forcing a full scan of the inner table. The overestimation, I think, is caused by a data skew: summarising estimation error on many partitions, we get an error that is worse than estimating once on a plain table.
Partitioning (64 partitions case)
To test these conjectures, let's try to increase the number of partitions enough to highlight the effect but not so big to get stuck in optimisation complexity, which still consumes many CPU and memory resources on thousands of partitions. Using this script, let's generate 64 partitions on each big table and skip partitioning for tiny tables to get closer to reality. See on the graph below how partitioning changed execution time:
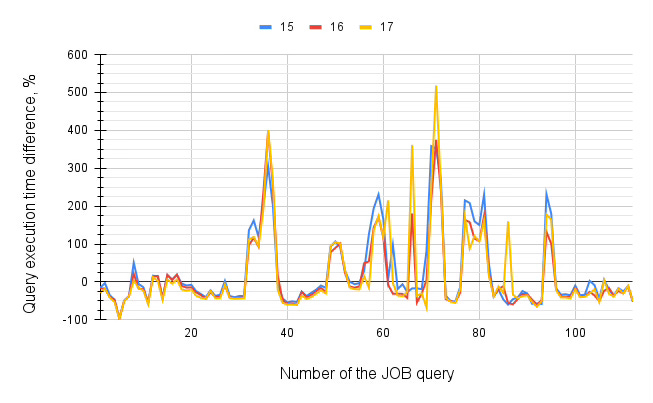
You can see that many queries speed up a bit, but some queries become slower, around 100 - 500%. Check some query plans to find a reason.
After glancing at the plan of five arbitrarily chosen 'good' queries, I can say that the key reason for the speedup is the spotting of reads. Although the optimiser couldn't prune partitions in the initial phase, the parameterised NestLoop chose only one specific partition each time, which reduced scanning efforts. It also improved the "buffer hits" statistics, influencing execution time. That's an excellent example of what a DBA awaits when performing a table split between partitions. But what about slowing down queries?
Performance slump looks worse with 64 partitions. Let's compare a parallel sequential scan of a plain table and an appended one with the same data:
-> Parallel Seq Scan on movie_info
(actual time=579..1714 rows=23159 loops=3)-> Parallel Append
(actual time=8285..9774 rows=23159 loops=3)
-> Parallel Seq Scan on movie_info_part_13
(actual time=8158..8245 rows=1084 loops=1)
-> Parallel Seq Scan on movie_info_part_35
(actual time=0.135..75 rows=1096 loops=1)
-> Parallel Seq Scan on movie_info_part_26
(actual time=8576..8650 rows=1086 loops=1)
-> Parallel Seq Scan on movie_info_part_4
(actual time=0.136..23 rows=332 loops=3)
...As you can see, some partitions that returned the same number of tuples were executed 100 times faster than the slower ones! It looks like a parallel execution skew problem, but with the same probability, it may just be a bug. And, as in the two partitions case, we see how long it takes to produce the first tuple for some partitions.
Cost estimation also is affected by a reason:
-> Parallel Append (cost=0.00..271597.22 rows=164209 width=8)
-> Parallel Seq Scan on movie_info_part_13
-> ...
-> Parallel Seq Scan on movie_info (cost=0.00..241078.30 rows=32517)It is not a big issue because, in many cases, it provides an even more precise estimation than in the single plain table case. But sometimes, it triggers an insufficient query plan decision, which should henceforth be discovered.
One sad outcome I got is a selection of one tuple: with partitions, even with unique indexes on all partitions, the optimiser still predicts no fewer tuples than the number of partitions. Many wrong decisions in these runs came from choosing Parallel Hash Join instead of optimal and spotting NestLoop.
Note that I didn’t find the Memoize node even once over the appended table - is it a limitation or a game of chance?
Conclusions
First and foremost, this benchmark shows very volatile results in execution time and stability of query plan. It is necessary to use it carefully and always perform preliminary tuning.
My second outcome - local partitioning in PostgreSQL looks mature: I didn’t see huge mishaps or overconsumption of resources during planning.
With all that said, we still have unclear issues with load balancing in the case of parallel append, which triggers most performance degradation cases. Also, we have to work on the 1-tuple problem, which leads to choosing HashJoin instead of NestLoop. The last possible issue is statistics usage on partitioned tables.
Also, I didn’t observe any partitionwise joins there. Maybe the Asymmetric Partitionwise Join feature could bring some profit there?
P.S. All raw data can be found here.
THE END.
July 21, 2024. Thailand, South Pattaya.
In the end, I realised it is more stable to execute one query ten times before switching to another one instead of passing all the queries ten times. However, the essence of the problem still impacts the query execution time much more, so we stay with the current benchmarking script.